Full fidelity
full fidelity モードを使用すると、 W&B はデータポイントの数に基づいて x 軸を動的なバケットに分割します。次に、折れ線グラフの point aggregation をレンダリングする際に、各バケット内の最小値、最大値、平均値を算出します。 point aggregation に full fidelity モードを使用することには、主に 3 つの利点があります。- 極端な値やスパイクを保持:データ内の極端な値やスパイクを維持します。
- 最小値と最大値の描画設定: W&B App を使用して、極端な値(最小値/最大値)をシェーディング領域として表示するかどうかをインタラクティブに決定できます。
- データの忠実度を損なわずに探索:特定のデータポイントにズームインすると、 W&B は x 軸のバケットサイズを再計算します。これにより、精度を落とさずにデータを探索できるようになります。以前に計算された集計を保存するためにキャッシングが使用され、読み込み時間を短縮します。これは特に大きな Datasets をナビゲートする場合に有効です。
最小値と最大値の描画設定
折れ線グラフの周囲にシェーディング領域を表示して、最小値と最大値を表示または非表示にします。 以下の画像は青い折れ線グラフを示しています。水色のシェーディング領域は、各バケットの最小値と最大値を表しています。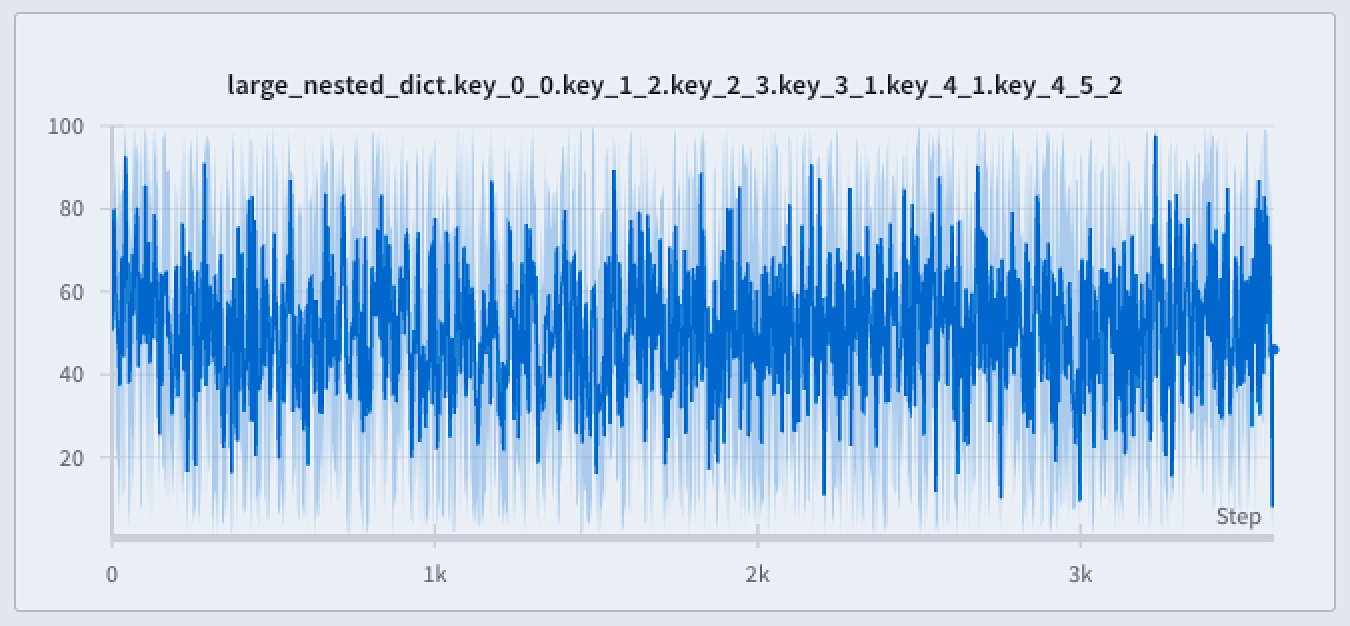
- Never: 最小値/最大値はシェーディング領域として表示されません。 x 軸のバケット全体の集計ラインのみが表示されます。
- On hover: チャート上にホバーしたときに、最小値/最大値のシェーディング領域が動的に表示されます。このオプションは、インタラクティブに範囲を確認できるようにしつつ、ビューをすっきりと保ちます。
- Always: チャート内のすべてのバケットに対して最小値/最大値のシェーディング領域が常に表示され、常に全範囲の値を可視化するのに役立ちます。チャート内で多くの Runs が可視化されている場合、視覚的な ノイズ になる可能性があります。
- Workspace内のすべてのチャート
- Workspace内の個別のチャート
- W&B の Projects に移動します
- 左タブの Workspace アイコンを選択します
- 画面右上の Add panels ボタンの左隣にある歯車アイコンを選択します。
- 表示される UI スライダーから、 Line plots を選択します
- Point aggregation セクション内の Show min/max values as a shaded area ドロップダウンメニューから、 On hover または Always を選択します。
データの忠実度を損なわずに探索
極端な値やスパイクなどの重要なポイントを見逃すことなく、 Dataset の特定の領域を分析できます。折れ線グラフをズームインすると、 W&B は各バケット内の最小値、最大値、平均値を計算するために使用されるバケットサイズを調整します。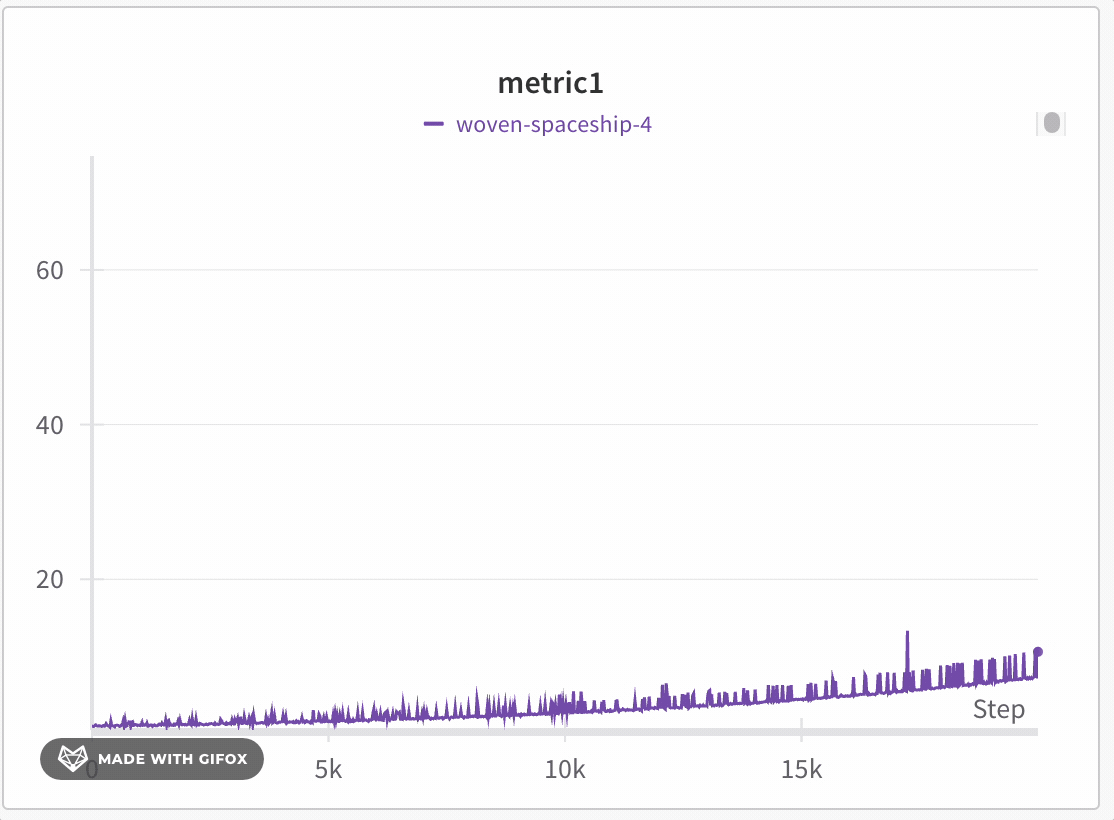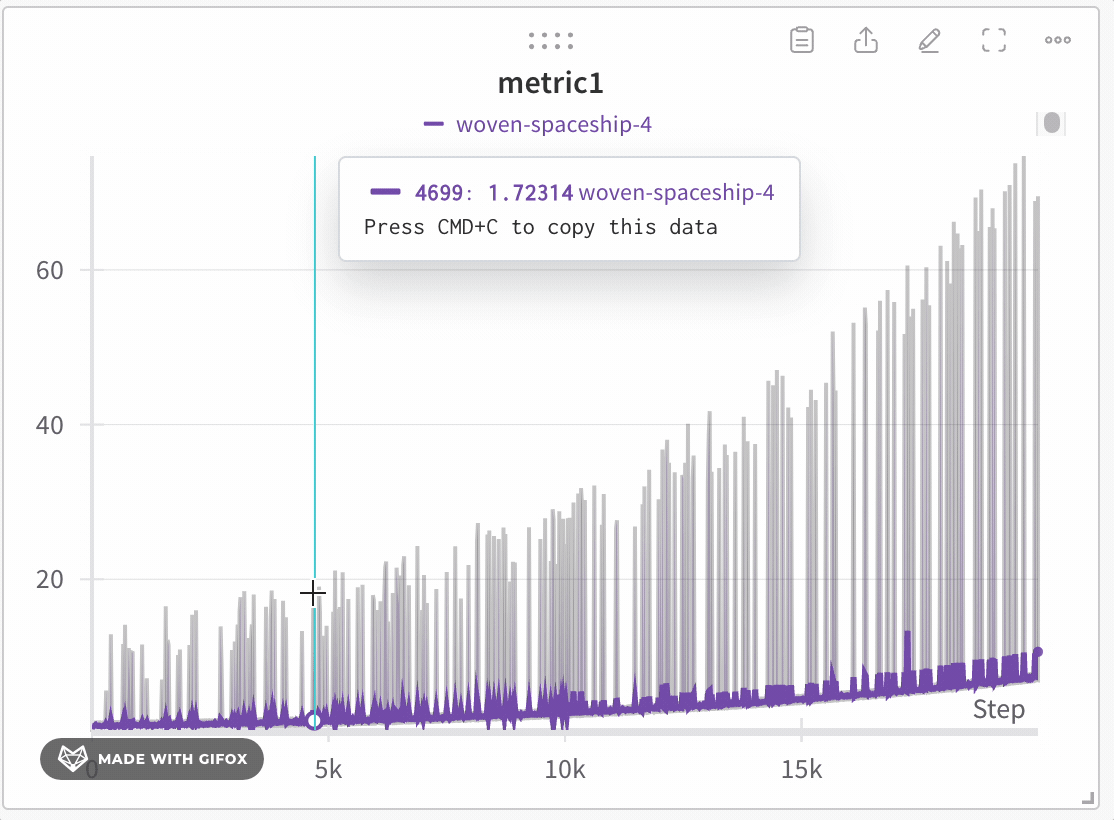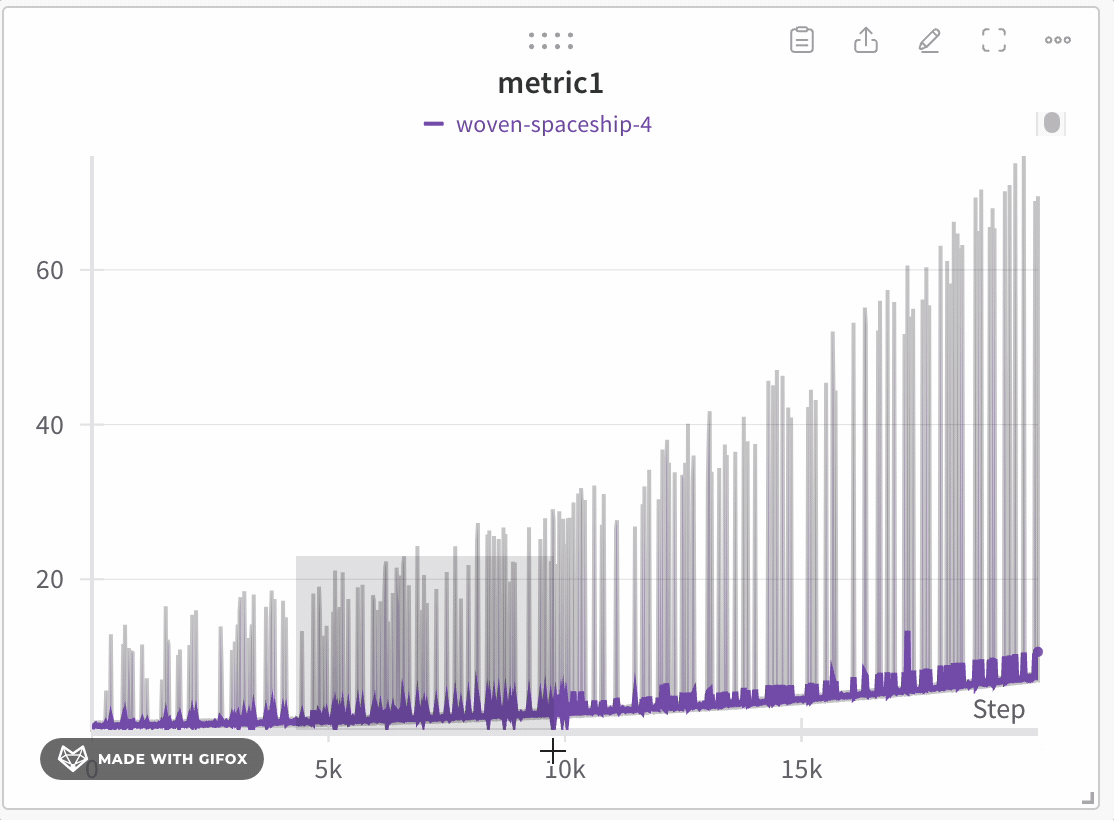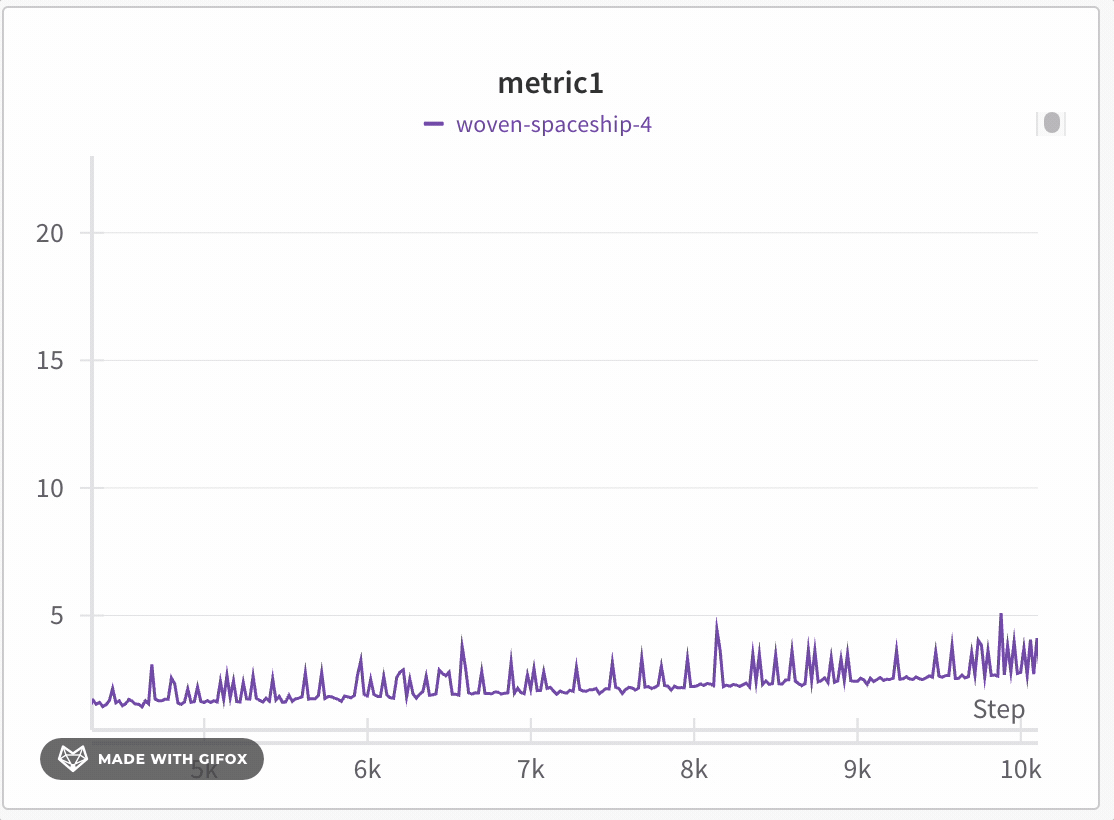
- Minimum: そのバケット内の最小値。
- Maximum: そのバケット内の最大値。
- Average: そのバケット内のすべてのポイントの平均値。
- W&B の Projects に移動します
- 左タブの Workspace アイコンを選択します
- 必要に応じて Workspace に折れ線グラフ パネルを追加するか、既存の折れ線グラフ パネルに移動します。
- クリックしてドラッグし、ズームインしたい特定の領域を選択します。
折れ線グラフのグルーピングと式折れ線グラフのグルーピングを使用する場合、 W&B は選択されたモードに基づいて以下を適用します。
- Non-windowed sampling (grouping): x 軸上の Runs 間でポイントを整列させます。複数のポイントが同じ x 値を共有している場合は平均が取られ、そうでない場合は個別のポイントとして表示されます。
- Windowed sampling (grouping and expressions): x 軸を 250 個のバケット、または最も長いラインのポイント数(のいずれか小さい方)に分割します。 W&B は各バケット内のポイントの平均を取ります。
- Full fidelity (grouping and expressions): non-windowed sampling と同様ですが、パフォーマンスと詳細のバランスをとるために、 Run あたり最大 500 ポイントを取得します。
Random sampling
Random sampling は、折れ線グラフをレンダリングするためにランダムにサンプリングされた 1500 個のポイントを使用します。 Random sampling は、データポイントの数が多い場合にパフォーマンス上の理由で役立ちます。Random sampling を有効にする
デフォルトでは、 W&B は full fidelity モードを使用します。 Random sampling を有効にするには、以下の手順に従ってください。- Workspace内のすべてのチャート
- Workspace内の個別のチャート
- W&B の Projects に移動します
- 左タブの Workspace アイコンを選択します
- 画面右上の Add panels ボタンの左隣にある歯車アイコンを選択します。
- 表示される UI スライダーから、 Line plots を選択します
- Point aggregation セクションから Random sampling を選択します