Embedding の例
Hello World
W&B では、wandb.Table クラスを使用して embeddings を ログ に記録できます。それぞれ 5 つの次元を持つ 3 つの embeddings の次の例を考えてみましょう。
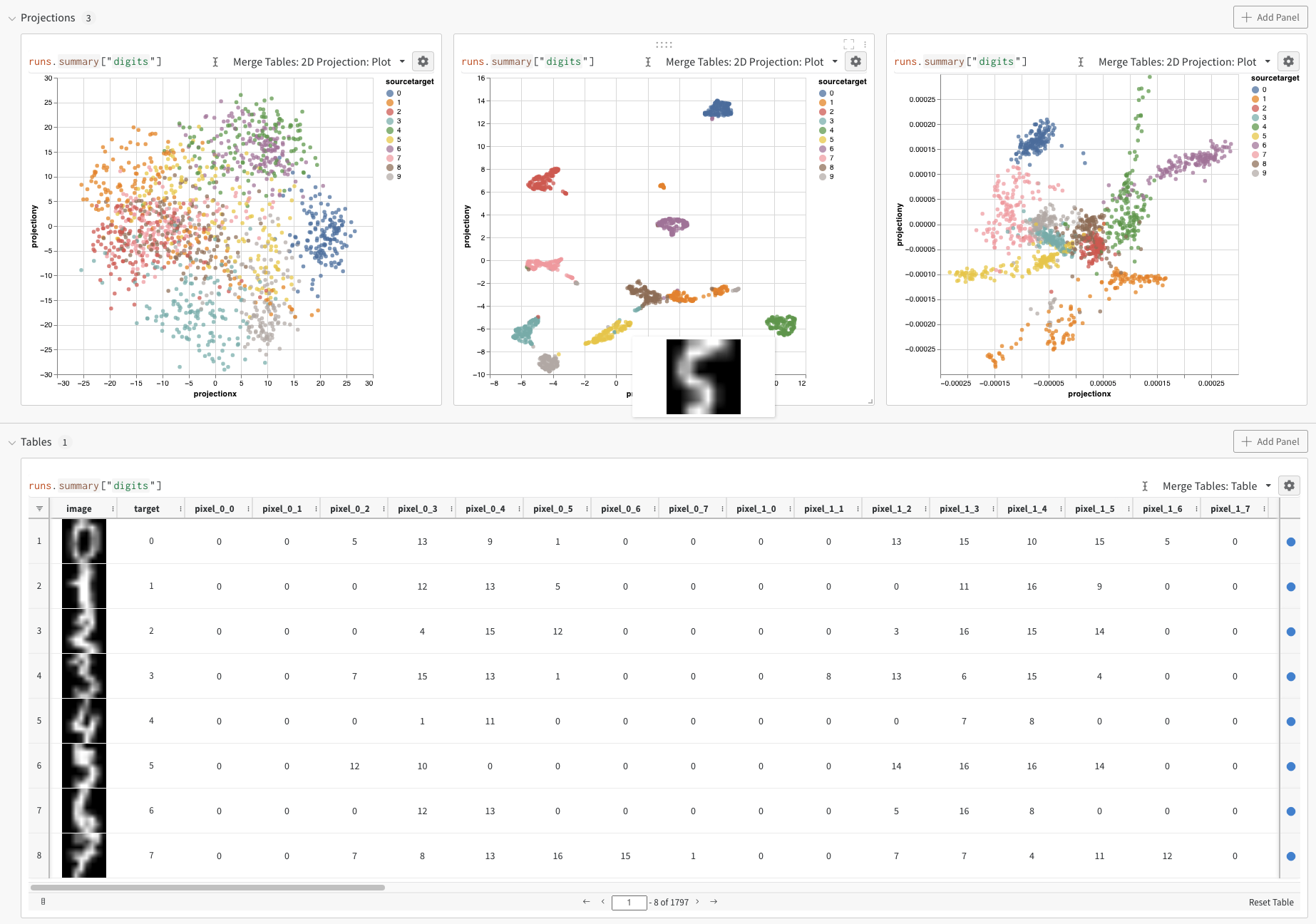
2D Projection を選択すると、embeddings を 2 次元でプロットできます。最適なデフォルト設定が自動的に選択されますが、ギアアイコンをクリックしてアクセスできる設定メニューで簡単に変更できます。この例では、利用可能な 5 つの数値次元すべてが自動的に使用されます。
Digits MNIST
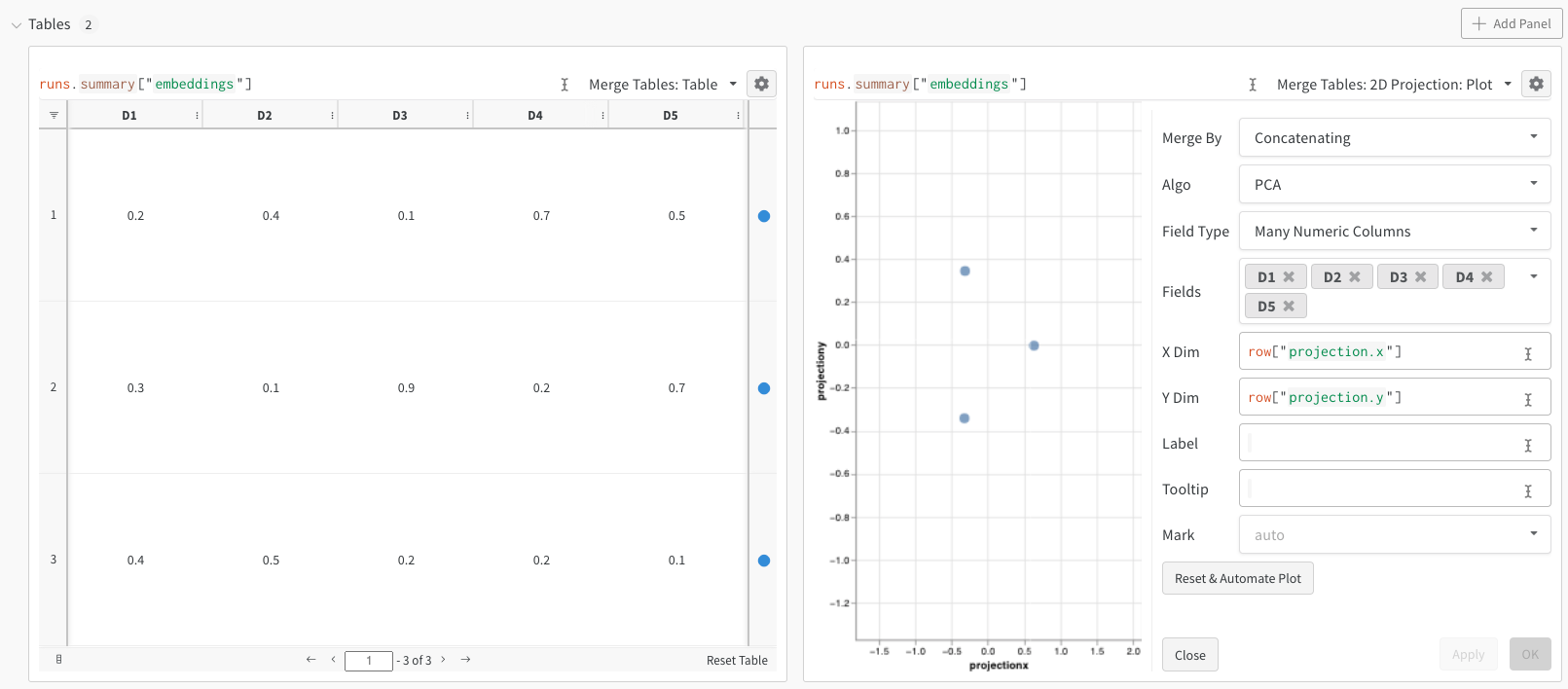
上記の例は embeddings を ログ に記録する基本的な仕組みを示していますが、通常はより多くの次元とサンプルを扱います。 SciKit-Learn 経由で利用可能な MNIST Digits データセット( UCI ML 手書き数字データセット )を例に考えてみましょう。この データセット には 1797 件のレコードがあり、それぞれ 64 の次元を持っています。この問題は 10 クラスの分類ユースケースです。入力データを可視化のために画像に変換することもできます。2D Projection を選択することで、embedding の定義、色付け、アルゴリズム(PCA、UMAP、t-SNE)、アルゴリズム パラメータ 、さらにはオーバーレイ(この例ではポイントをホバーしたときに画像を表示する)を 設定 できます。この特定のケースでは、これらはすべて「スマートなデフォルト設定」になっており、 2D Projection を 1 回クリックするだけで、これに近いものが表示されるはずです。( この embedding チュートリアルの例を操作する )。
ログ記録のオプション
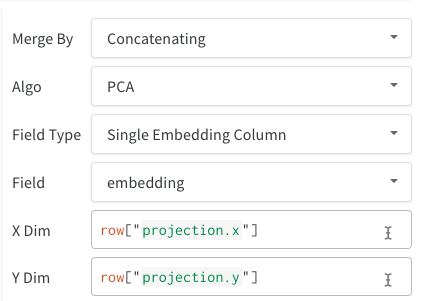
embeddings はいくつかの異なる形式で ログ に記録できます。- 単一の Embedding 列: データがすでに「行列」のような形式になっている場合が多いです。この場合、単一の embedding 列を作成できます。セルのデータの型は
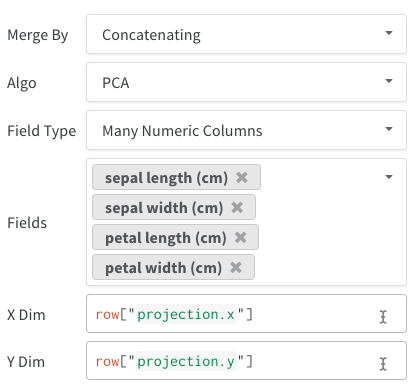
list[int]、list[float]、またはnp.ndarrayになります。 - 複数の数値列: 上記の 2 つの例では、このアプローチを使用して、各次元に対して列を作成しました。現在、セルの値として python の
intまたはfloatを受け付けています。
wandb.Table(dataframe=df)を使用して dataframe から直接作成するwandb.Table(data=[...], columns=[...])を使用して データリスト から直接作成する- 1行ずつ増分的に テーブルを構築する(コード内にループがある場合に最適)。
table.add_data(...)を使用してテーブルに行を追加します。 - テーブルに embedding 列 を追加する(embeddings 形式の予測リストがある場合に最適):
table.add_col("col_name", ...) - 計算列 を追加する(テーブル全体にマップしたい関数や モデル がある場合に最適):
table.add_computed_columns(lambda row, ndx: {"embedding": model.predict(row)})
プロットのオプション
2D Projection を選択した後、ギアアイコンをクリックしてレンダリング設定を編集できます。対象の列を選択する(上記参照)ことに加え、目的のアルゴリズム(および必要な パラメータ )を選択できます。以下に、それぞれ UMAP と t-SNE の パラメータ を示します。
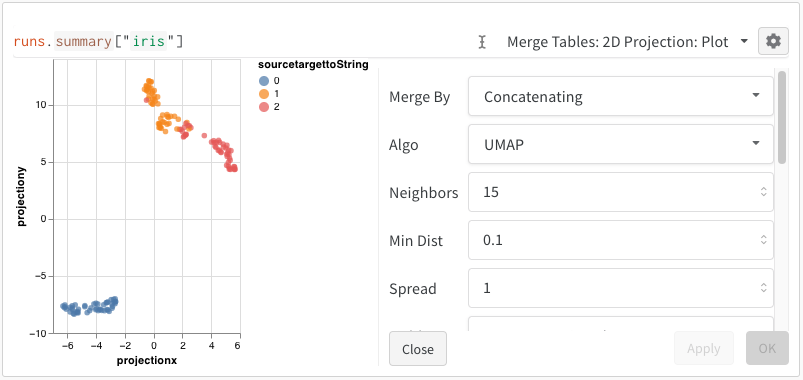
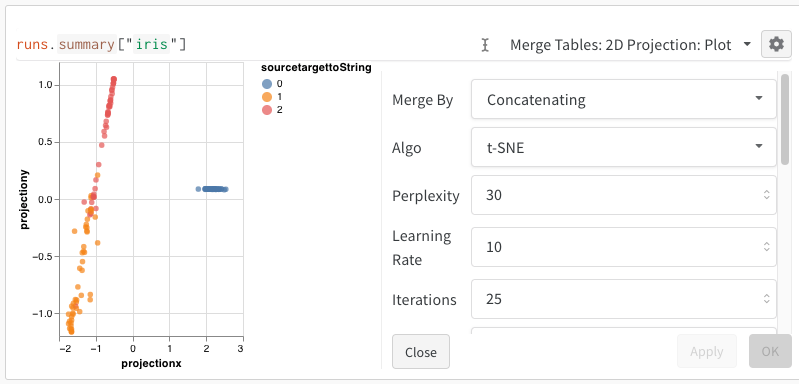
注:現在、3つのアルゴリズムすべてにおいて、ランダムな 1000 行、50 次元の サブセット にダウンサンプリングされます。