주요 아티클
모든 카테고리에서 가장 자주 묻는 질문들입니다.wandb.init이 내 트레이닝 프로세스에 어떤 영향을 주나요?- Sweeps에서 커스텀 CLI 커맨드를 어떻게 사용하나요?
- 메트릭을 오프라인으로 저장하고 나중에 W&B에 동기화할 수 있나요?
- 트레이닝 코드에서 run의 이름을 어떻게 설정할 수 있나요?
여전히 찾으시는 내용을 찾을 수 없나요?
학생으로서 아카데믹 플랜을 받을 수 있나요?
학생으로서 아카데믹 플랜을 받을 수 있나요?
- wandb.com의 가격 책정 페이지를 방문하세요.
- 아카데믹 플랜을 신청하세요.
- 또는 30일 트라이얼로 시작한 후 W&B 아카데믹 신청 페이지를 방문하여 아카데믹 플랜으로 전환하세요.
누가 내 Artifacts에 엑세스할 수 있나요?
누가 내 Artifacts에 엑세스할 수 있나요?
- 프라이빗 프로젝트에서는 Teams 멤버들만 Artifacts에 엑세스할 수 있습니다.
- 퍼블릭 프로젝트에서는 모든 Users가 Artifacts를 읽을 수 있으며, Teams 멤버들만 생성하거나 수정할 수 있습니다.
- 오픈 프로젝트에서는 모든 Users가 Artifacts를 읽고 쓸 수 있습니다.
Artifacts 워크플로우
이 섹션에서는 Artifacts를 관리하고 편집하기 위한 워크플로우를 설명합니다. 많은 워크플로우가 W&B에 저장된 데이터에 엑세스할 수 있게 해주는 client library의 구성 요소인 W&B API를 활용합니다.내 Runs에 로그된 데이터에 직접 프로그래밍 방식으로 엑세스하려면 어떻게 해야 하나요?
내 Runs에 로그된 데이터에 직접 프로그래밍 방식으로 엑세스하려면 어떻게 해야 하나요?
wandb.log로 로그된 메트릭을 추적합니다. API를 사용하여 history 오브젝트에 엑세스하세요:Sweep에 추가 값을 더할 수 있는 방법이 있나요, 아니면 새로 시작해야 하나요?
Sweep에 추가 값을 더할 수 있는 방법이 있나요, 아니면 새로 시작해야 하나요?
시트(seats)를 추가할 수 있는 방법이 있나요?
시트(seats)를 추가할 수 있는 방법이 있나요?
- 지원을 받으려면 어카운트 익제큐티브(Account Executive) 또는 지원팀 (support@wandb.com)에 문의하세요.
- 조직 이름과 원하는 시트 수를 제공하세요.
Tables에 Plotly 또는 Bokeh 차트를 어떻게 추가하나요?
Tables에 Plotly 또는 Bokeh 차트를 어떻게 추가하나요?
- Plotly 사용
- Bokeh 사용
동일한 서비스 계정을 여러 팀에 추가할 수 있나요?
동일한 서비스 계정을 여러 팀에 추가할 수 있나요?
Report에 여러 공동 저자 추가하기
Report에 여러 공동 저자 추가하기

Weights and Biases용 anaconda 패키지가 있나요?
Weights and Biases용 anaconda 패키지가 있나요?
pip 또는 conda를 사용하여 설치할 수 있는 anaconda 패키지가 있습니다. conda의 경우, conda-forge 채널에서 패키지를 받으세요.- pip
- conda
익명 사용자(anonymous users)가 사용할 수 없는 기능은 무엇인가요?
익명 사용자(anonymous users)가 사용할 수 없는 기능은 무엇인가요?
- 데이터 비영구성: 익명 계정의 Runs는 7일 동안만 저장됩니다. 익명 run 데이터를 실제 계정에 저장하여 소유권을 주장하세요.
-
Artifact 로깅 불가: 익명 run에 Artifact를 로그하려고 하면 커맨드라인에 경고가 나타납니다:
- 프로필 또는 설정 페이지 없음: 실제 계정에서만 유용한 특정 페이지들은 UI에 포함되지 않습니다.
각 Artifact 버전은 얼마나 많은 스토리지를 사용하나요?
각 Artifact 버전은 얼마나 많은 스토리지를 사용하나요?

cat.png와 dog.png라는 두 개의 이미지 파일을 포함하는 animals라는 이미지 Artifact를 가정해 보겠습니다:v0를 부여받습니다.새로운 이미지 rat.png를 추가하면, 다음과 같은 내용으로 새로운 Artifact 버전 v1이 생성됩니다:v1은 총 6MB를 추적하지만, 나머지 3MB를 v0와 공유하므로 실제로는 3MB의 공간만 차지합니다. v1을 삭제하면 rat.png와 관련된 3MB의 스토리지가 반환됩니다. v0를 삭제하면 cat.png와 dog.png의 스토리지 비용이 v1으로 이전되어, v1의 스토리지 크기가 6MB로 증가합니다.여러 아키텍처와 Runs에서 Artifacts를 사용하려면 어떻게 해야 하나요?
여러 아키텍처와 Runs에서 Artifacts를 사용하려면 어떻게 해야 하나요?
- 각기 다른 모델 아키텍처에 대해 새로운 Artifact를 생성합니다. run의
config를 사용하는 것과 유사하게, Artifact의metadata속성을 사용하여 아키텍처에 대한 상세 설명을 제공하세요. - 각 모델에 대해
log_artifact를 사용하여 주기적으로 체크포인트를 로그합니다. W&B는 이러한 체크포인트의 이력을 구축하며, 가장 최근의 것에latest에일리어스를 라벨링합니다.architecture-name:latest를 사용하여 어떤 모델 아키텍처의 최신 체크포인트든 참조할 수 있습니다.
Sweep 내의 Runs에서 모델을 가장 잘 로그하는 방법은 무엇인가요?
Sweep 내의 Runs에서 모델을 가장 잘 로그하는 방법은 무엇인가요?
하이퍼파라미터 검색을 정리하는 모범 사례
하이퍼파라미터 검색을 정리하는 모범 사례
wandb.init(tags='your_tag')를 사용하여 고유한 태그를 설정하세요. 이를 통해 프로젝트 페이지의 Runs 테이블에서 해당 태그를 선택하여 프로젝트 Runs를 효율적으로 필터링할 수 있습니다.wandb.init()에 대한 자세한 내용은 wandb.init() 레퍼런스를 참조하세요.구독을 취소하려면 어떻게 해야 하나요?
구독을 취소하려면 어떻게 해야 하나요?
- 지원팀 (support@wandb.com)에 문의하세요.
- 조직 이름, 계정과 연결된 이메일, 그리고 사용자 이름을 제공하세요.
계정을 기업용에서 아카데믹 플랜으로 변경하려면 어떻게 해야 하나요?
계정을 기업용에서 아카데믹 플랜으로 변경하려면 어떻게 해야 하나요?
-
아카데믹 이메일 연결:
- 계정 설정에 접속합니다.
- 아카데믹 이메일을 추가하고 기본 이메일로 설정합니다.
-
아카데믹 플랜 신청:
- W&B 아카데믹 신청 페이지를 방문합니다.
- 검토를 위해 신청서를 제출합니다.
청구 주소를 어떻게 변경하나요?
청구 주소를 어떻게 변경하나요?
Sweep이 로컬에 로그를 남기는 디렉토리를 어떻게 변경할 수 있나요?
Sweep이 로컬에 로그를 남기는 디렉토리를 어떻게 변경할 수 있나요?
WANDB_DIR을 설정하여 W&B run 데이터의 로깅 디렉토리를 구성하세요. 예시:완료된 run에 할당된 그룹을 나중에 변경할 수 있나요?
완료된 run에 할당된 그룹을 나중에 변경할 수 있나요?
사용자 이름을 변경할 수 있나요?
사용자 이름을 변경할 수 있나요?
W&B 클라이언트는 Python 2를 지원하나요?
W&B 클라이언트는 Python 2를 지원하나요?
pip install --upgrade wandb를 실행하면 0.10.x 시리즈의 최신 릴리스만 설치됩니다. 0.10.x 시리즈에 대한 지원은 크리티컬 버그 수정 및 패치로만 제한됩니다. Python 2.7을 지원하는 0.10.x 시리즈의 마지막 버전은 0.10.33입니다.W&B 클라이언트는 Python 3.5를 지원하나요?
W&B 클라이언트는 Python 3.5를 지원하나요?
에포크(epochs)나 단계(steps)에 걸쳐 이미지나 미디어를 어떻게 비교하나요?
에포크(epochs)나 단계(steps)에 걸쳐 이미지나 미디어를 어떻게 비교하나요?
트레이닝 코드에서 run의 이름을 어떻게 설정할 수 있나요?
트레이닝 코드에서 run의 이름을 어떻게 설정할 수 있나요?
wandb.init을 호출하세요. 예: wandb.init(name="my_awesome_run").Report를 WYSIWYG으로 전환했는데 다시 Markdown으로 되돌리고 싶습니다
Report를 WYSIWYG으로 전환했는데 다시 Markdown으로 되돌리고 싶습니다
cmd+z를 사용하여 실행 취소하세요.세션이 닫혀서 되돌리기 옵션을 사용할 수 없는 경우, 초안을 폐기하거나 마지막으로 저장된 버전에서 편집하는 것을 고려해 보세요. 둘 다 작동하지 않으면 W&B 지원팀에 문의하세요.wandb가 충돌하면 내 트레이닝 run도 충돌할 수 있나요?
wandb가 충돌하면 내 트레이닝 run도 충돌할 수 있나요?
이전에 삭제된 계정에서 사용했던 이메일로 새 계정을 생성할 수 있나요?
이전에 삭제된 계정에서 사용했던 이메일로 새 계정을 생성할 수 있나요?
누가 팀을 생성할 수 있나요? 누가 팀에서 사람을 추가하거나 삭제할 수 있나요? 누가 프로젝트를 삭제할 수 있나요?
누가 팀을 생성할 수 있나요? 누가 팀에서 사람을 추가하거나 삭제할 수 있나요? 누가 프로젝트를 삭제할 수 있나요?
Sweeps에서 커스텀 CLI 커맨드를 어떻게 사용하나요?
Sweeps에서 커스텀 CLI 커맨드를 어떻게 사용하나요?
train.py라는 Python 스크립트를 트레이닝하고 스크립트가 파싱할 값을 제공하는 bash 터미널을 보여줍니다:command 키를 수정하세요. 이전 예시를 바탕으로 구성은 다음과 같습니다:${args} 키는 Sweep 구성의 모든 파라미터로 확장되며, argparse용 형식인 --param1 value1 --param2 value2로 포맷팅됩니다.argparse 외부의 추가 인수의 경우 다음과 같이 구현하세요:python이 Python 2를 참조할 수 있습니다. Python 3가 호출되도록 하려면 커맨드 구성에서 python3를 사용하세요:다크 모드가 있나요?
다크 모드가 있나요?
- W&B 계정 설정으로 이동합니다.
- Public preview features 섹션으로 스크롤합니다.
- UI Display에서 드롭다운 메뉴를 통해 Dark mode를 선택합니다.
네트워크 문제를 어떻게 처리하나요?
네트워크 문제를 어떻게 처리하나요?
wandb: Network error (ConnectionError), entering retry loop와 같은 SSL 또는 네트워크 오류가 발생하면 다음 해결 방법을 사용하세요:- SSL 인증서를 업그레이드합니다. Ubuntu 서버에서는
update-ca-certificates를 실행하세요. 보안 위험을 완화하고 트레이닝 로그를 동기화하기 위해 유효한 SSL 인증서가 필수적입니다. - 네트워크 연결이 불안정한 경우, 선택적 환경 변수
WANDB_MODE를offline으로 설정하여 오프라인 모드에서 작업하고, 나중에 인터넷 연결이 가능한 장치에서 파일을 동기화하세요. - 로컬에서 실행되어 클라우드 서버와의 동기화를 피할 수 있는 W&B Private Hosting 사용을 고려해 보세요.
SSL CERTIFICATE_VERIFY_FAILED 오류의 경우, 회사 방화벽으로 인해 발생할 수 있습니다. 로컬 CA를 구성하고 다음을 실행하세요:export REQUESTS_CA_BUNDLE=/etc/ssl/certs/ca-certificates.crt커스텀 차트 프리셋을 어떻게 삭제하나요?
커스텀 차트 프리셋을 어떻게 삭제하나요?
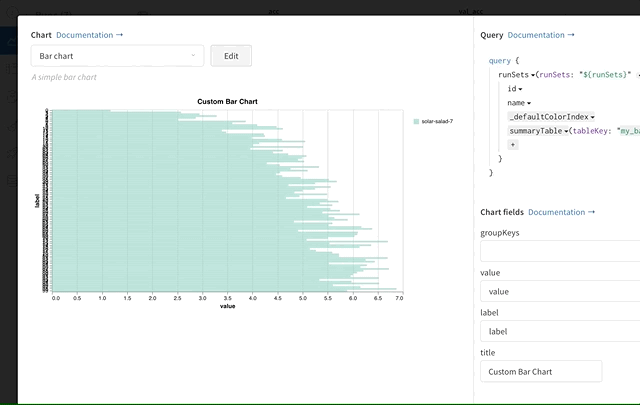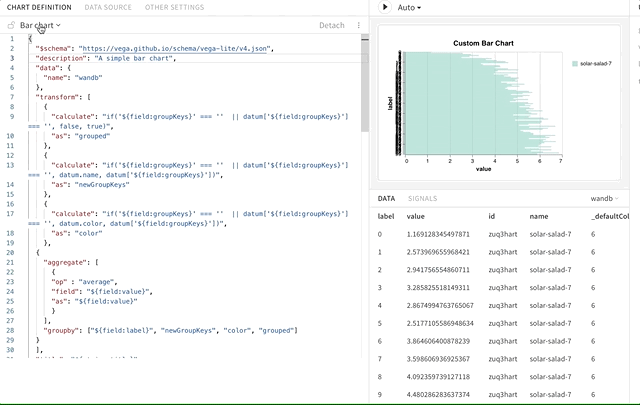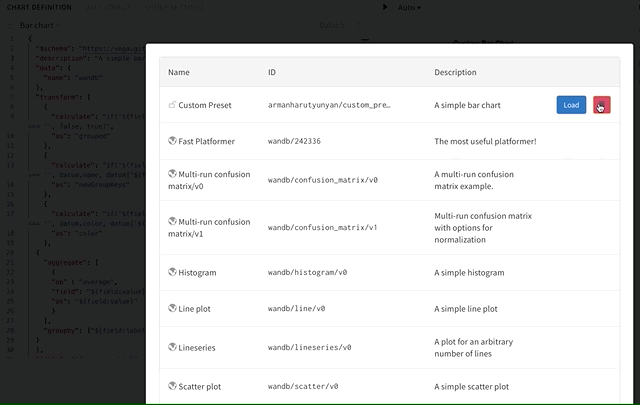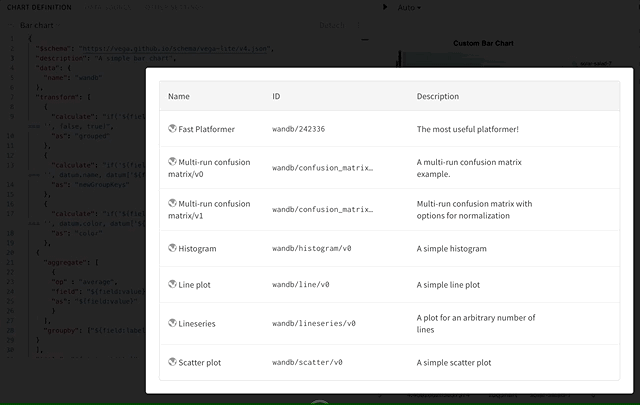
조직 계정을 어떻게 삭제하나요?
조직 계정을 어떻게 삭제하나요?
패널 그리드를 어떻게 삭제하나요?
패널 그리드를 어떻게 삭제하나요?
내 계정에서 팀을 어떻게 삭제하나요?
내 계정에서 팀을 어떻게 삭제하나요?
- 관리자 권한으로 팀 설정에 접속합니다.
- 페이지 하단의 Delete 버튼을 클릭합니다.
run에 이름을 짓지 않았는데, run 이름은 어디서 오는 건가요?
run에 이름을 짓지 않았는데, run 이름은 어디서 오는 건가요?
pleasant-flower-4 및 misunderstood-glade-2 등이 있습니다.`.log()`와 `.summary`의 차이점은 무엇인가요?
`.log()`와 `.summary`의 차이점은 무엇인가요?
run.log()를 호출합니다. 기본적으로 run.log()는 해당 메트릭에 대해 수동으로 설정하지 않는 한 summary 값을 업데이트합니다.산점도(scatterplot)와 평행 좌표계 플롯(parallel coordinate plots)은 summary 값을 사용하고, 라인 플롯(line plot)은 run.log에 기록된 모든 값을 표시합니다.일부 사용자들은 가장 최근에 로그된 정확도 대신 최적의 정확도를 반영하기 위해 summary를 수동으로 설정하는 것을 선호합니다.팀(team)과 엔티티(entity)의 차이점은 무엇인가요? 사용자로서 엔티티는 저에게 무엇을 의미하나요?
팀(team)과 엔티티(entity)의 차이점은 무엇인가요? 사용자로서 엔티티는 저에게 무엇을 의미하나요?
wandb.init(entity="example-team")을 사용하여 엔티티를 개인 계정 또는 팀 계정으로 설정하세요.팀(team)과 조직(organization)의 차이점은 무엇인가요?
팀(team)과 조직(organization)의 차이점은 무엇인가요?
wandb.init 모드들 사이의 차이점은 무엇인가요?
wandb.init 모드들 사이의 차이점은 무엇인가요?
online(기본값): 클라이언트가 데이터를 wandb 서버로 보냅니다.offline: 클라이언트가 데이터를 wandb 서버로 보내는 대신 로컬 머신에 저장합니다. 나중에wandb sync커맨드를 사용하여 데이터를 동기화하세요.disabled: 클라이언트가 mocked 오브젝트를 반환하여 작동을 시뮬레이션하고 모든 네트워크 통신을 차단합니다. 모든 로깅은 꺼지지만, 모든 API 메소드 스텁(stubs)은 계속 호출 가능합니다. 이 모드는 주로 테스트용으로 사용됩니다.
W&B는 TensorBoard와 어떻게 다른가요?
W&B는 TensorBoard와 어떻게 다른가요?
- 모델 재현성(Model Reproducibility): W&B는 실험, 탐색 및 모델 재현을 촉진합니다. 메트릭, 하이퍼파라미터, 코드 버전을 캡처하고 모델 체크포인트를 저장하여 재현성을 보장합니다.
- 자동 정리: W&B는 시도된 모든 모델에 대한 개요를 제공하여 프로젝트 인수인계 및 휴가 시 워크플로우를 간소화하며, 오래된 실험의 재실행을 방지하여 시간을 절약해 줍니다.
- 빠른 인테그레이션: 5분 만에 프로젝트에 W&B를 인테그레이션하세요. 무료 오픈 소스 Python 패키지를 설치하고 코드 몇 줄만 추가하면 됩니다. 로그된 메트릭과 기록은 각 모델 run과 함께 나타납니다.
- 중앙 집중식 대시보드: 트레이닝이 로컬, 연구소 클러스터, 또는 클라우드 스팟 인스턴스 중 어디서 이루어지든 일관된 대시보드에 엑세스하세요. 여러 머신에서 TensorBoard 파일을 관리할 필요가 없습니다.
- 강력한 필터링 테이블: 다양한 모델의 결과를 효율적으로 검색, 필터링, 정렬 및 그룹화하세요. 대규모 프로젝트에서 TensorBoard가 어려움을 겪는 영역인 다양한 작업별 최적의 모델을 쉽게 식별할 수 있습니다.
- 협업 툴: W&B는 복잡한 기계학습 프로젝트를 위한 협업을 강화합니다. 프로젝트 링크를 공유하고 결과 공유를 위해 프라이빗 팀을 활용하세요. 업무 로그나 프레젠테이션을 위해 인터랙티브 시각화와 마크다운 설명이 포함된 Reports를 생성하세요.
구독 플랜을 어떻게 다운그레이드하나요?
구독 플랜을 어떻게 다운그레이드하나요?
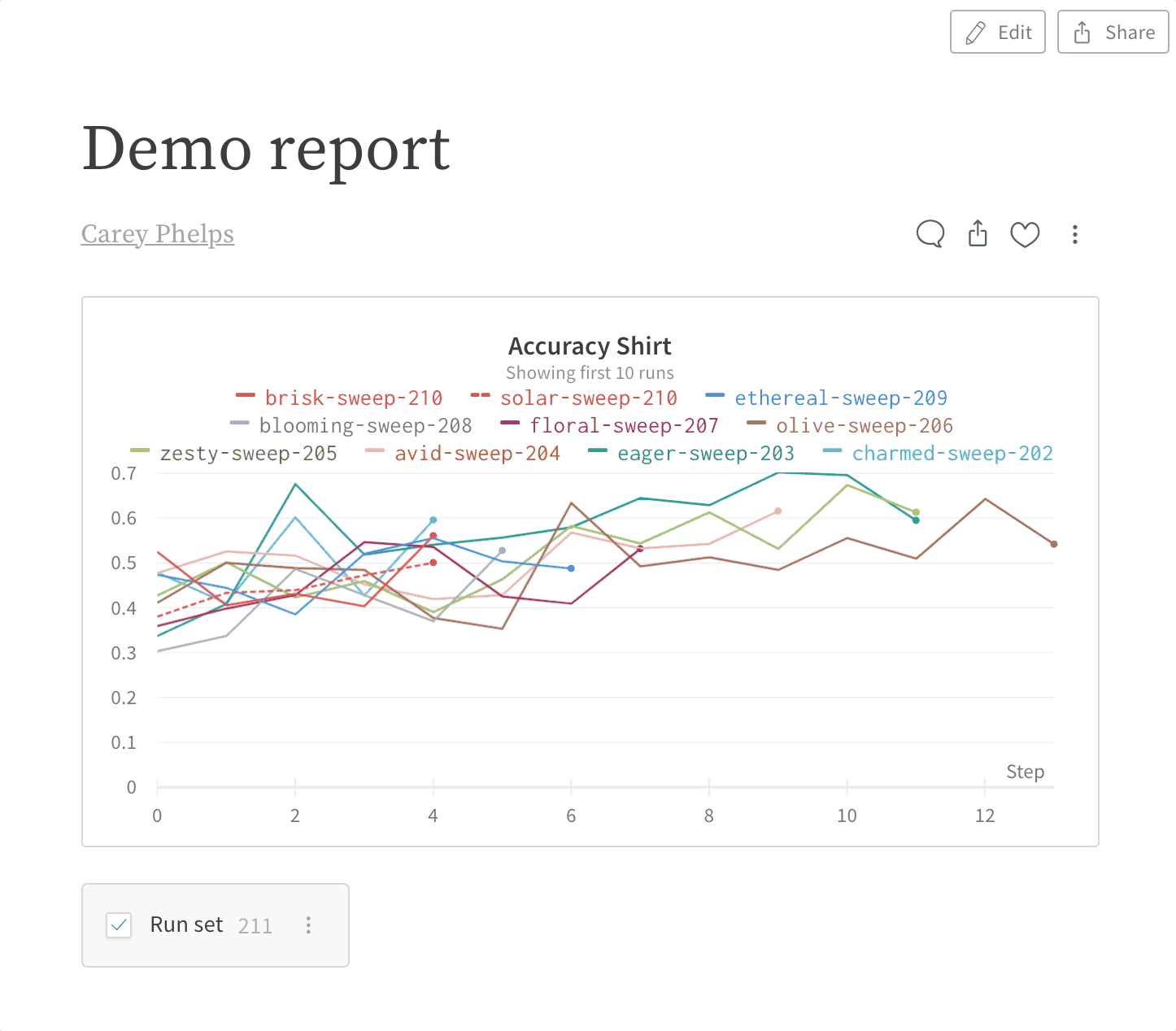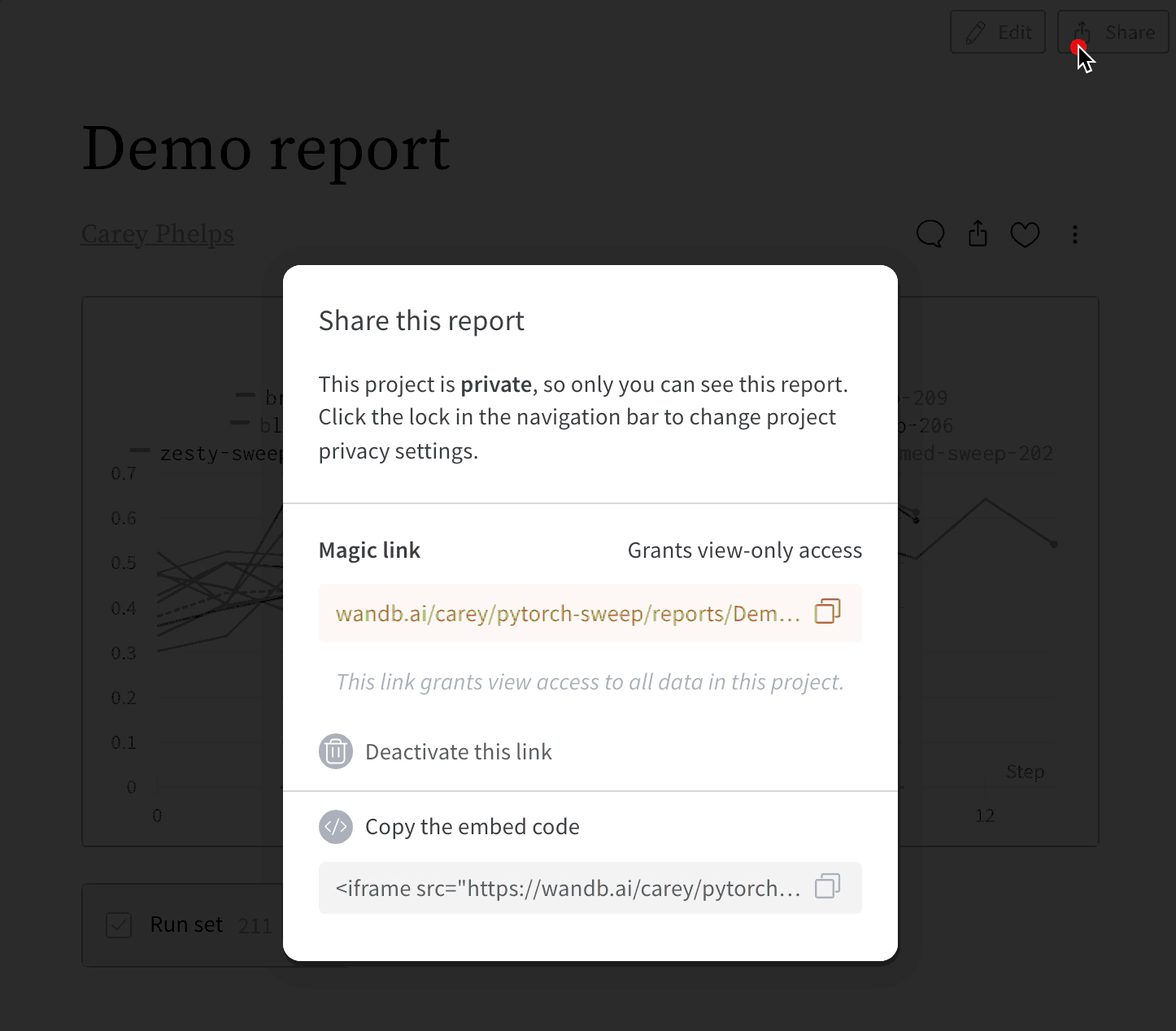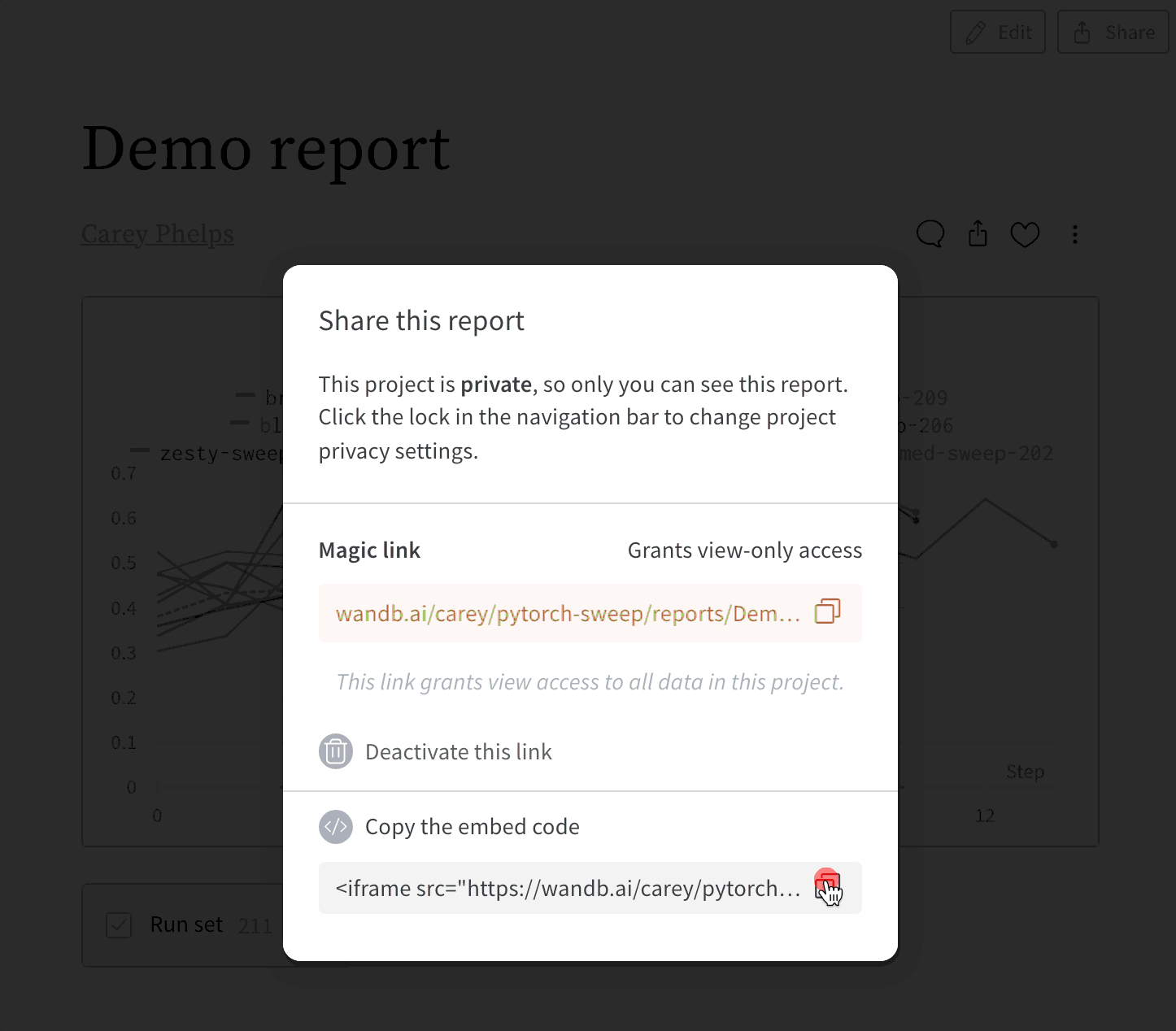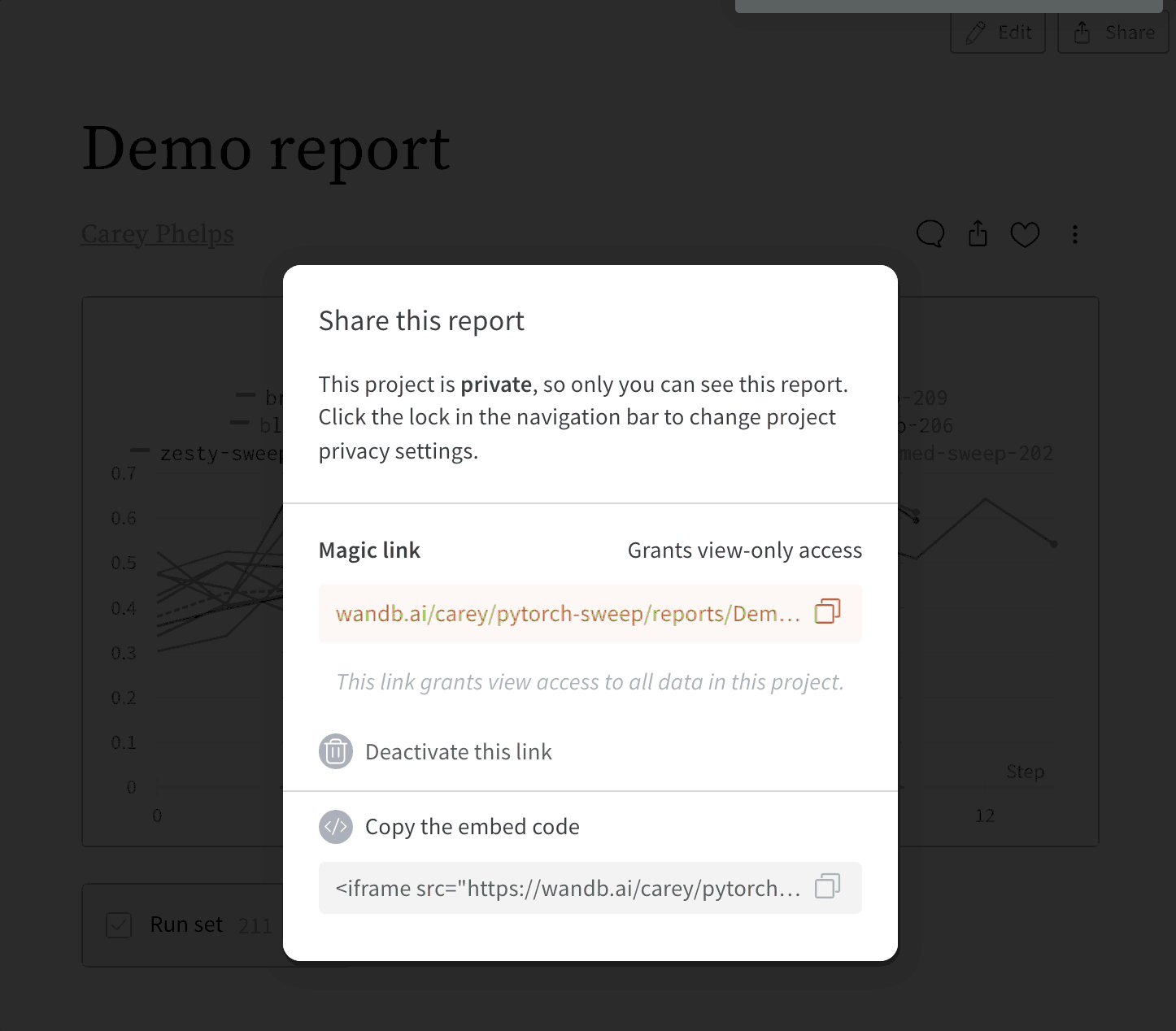
누가 Reports를 편집하고 공유할 수 있나요?
누가 Reports를 편집하고 공유할 수 있나요?
Reports 임베딩하기
Reports 임베딩하기
Sweeps에서 코드 로깅을 어떻게 활성화하나요?
Sweeps에서 코드 로깅을 어떻게 활성화하나요?
wandb.log_code()를 추가하세요. W&B 프로필 설정에서 코드 로깅이 활성화되어 있더라도 이 작업이 필요합니다. 고급 코드 로깅에 대해서는 여기의 wandb.log_code() 문서를 참조하세요.환경 변수가 wandb.init()에 전달된 파라미터를 덮어쓰나요?
환경 변수가 wandb.init()에 전달된 파라미터를 덮어쓰나요?
wandb.init에 전달된 인수는 환경 변수보다 우선합니다. 환경 변수가 설정되지 않았을 때 시스템 기본값 이외의 기본 디렉토리를 설정하려면, wandb.init(dir=os.getenv("WANDB_DIR", my_default_override))를 사용하세요.`Est. Runs` 컬럼은 무엇인가요?
`Est. Runs` 컬럼은 무엇인가요?


expected_run_count 속성을 사용하세요:W&B 조직에서 사용자 리스트를 어떻게 내보내나요?
W&B 조직에서 사용자 리스트를 어떻게 내보내나요?
W&B에서 이러한 Version IDs와 ETags를 어떻게 가져올 수 있나요?
W&B에서 이러한 Version IDs와 ETags를 어떻게 가져올 수 있나요?
코드가 충돌할 때 어떤 파일을 확인해야 하나요?
코드가 충돌할 때 어떤 파일을 확인해야 하나요?
wandb/run-<date>_<time>-<run-id>/logs에 있는 debug.log와 debug-internal.log를 확인하세요.Filestream rate limit exceeded 오류를 어떻게 해결하나요?
Filestream rate limit exceeded 오류를 어떻게 해결하나요?
- API 요청을 줄이기 위해 로깅 빈도를 줄이거나 로그를 배치(batch) 처리합니다.
- 동시 API 요청을 피하기 위해 실험 시작 시간을 시차를 두고 배치합니다.
- W&B 상태 업데이트를 확인하여 문제가 일시적인 서버 측 문제에서 발생한 것이 아닌지 확인합니다.
- 속도 제한 상향을 요청하려면 실험 설정 세부 정보와 함께 W&B 지원팀 (support@wandb.com)에 연락하세요.
원치 않는 Reports 필터링 및 삭제
원치 않는 Reports 필터링 및 삭제
내 API 키를 어디서 찾을 수 있나요?
내 API 키를 어디서 찾을 수 있나요?
- Organization admins can find or list API keys for all organization users and service accounts.
- Team admins can find or list API keys for service accounts in teams they administer.
- Non-admin users can find or list their own API keys.
- Personal API key
- Service account API key
- Log in to W&B, click your user profile icon, then click User Settings.
- Scroll to the API Keys section.
Sweep에서 가장 좋은 run의 Artifact를 어떻게 찾나요?
Sweep에서 가장 좋은 run의 Artifact를 어떻게 찾나요?
run에 의해 로그되거나 사용된 Artifacts를 어떻게 찾나요? Artifact를 생성하거나 사용한 Runs는 어떻게 찾나요?
run에 의해 로그되거나 사용된 Artifacts를 어떻게 찾나요? Artifact를 생성하거나 사용한 Runs는 어떻게 찾나요?
- Artifact에서 시작
- Run에서 시작
불리언(boolean) 변수를 하이퍼파라미터로 플래그할 수 있나요?
불리언(boolean) 변수를 하이퍼파라미터로 플래그할 수 있나요?
${args_no_boolean_flags} 매크로를 사용하세요. 이 매크로는 불리언 파라미터를 플래그로 자동 포함합니다. param이 True이면 커맨드는 --param을 받습니다. param이 False이면 플래그는 생략됩니다.스무딩(smoothing) 알고리즘에 어떤 공식을 사용하나요?
스무딩(smoothing) 알고리즘에 어떤 공식을 사용하나요?
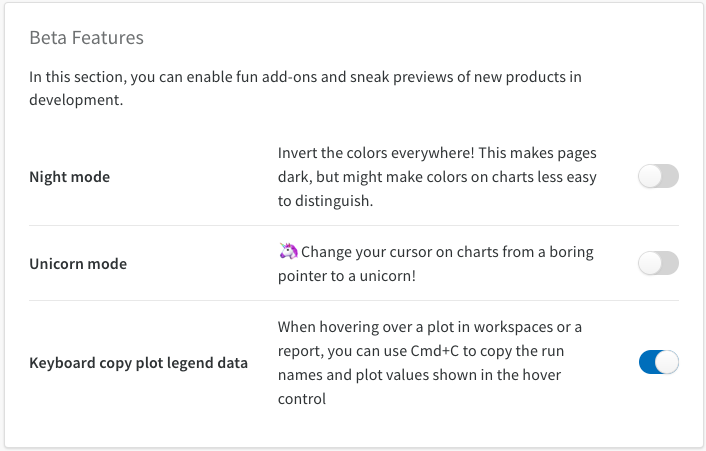
숨겨진 유용한 기능들은 무엇이며 어디서 찾을 수 있나요?
숨겨진 유용한 기능들은 무엇이며 어디서 찾을 수 있나요?
내 그래프에 왜 아무것도 표시되지 않나요?
내 그래프에 왜 아무것도 표시되지 않나요?
wandb.log 호출을 실행하지 않은 것입니다. 이 상황은 run이 한 스텝을 완료하는 데 시간이 오래 걸리는 경우 발생할 수 있습니다. 데이터 로깅을 서두르려면 에포크 끝에서만 로그하지 말고 에포크당 여러 번 로그하세요.동일한 그룹에 있는 각 run의 색상을 어떻게 변경할 수 있나요?
동일한 그룹에 있는 각 run의 색상을 어떻게 변경할 수 있나요?
'Group' 기능을 사용하지 않고 Runs를 그룹화할 수 있나요?
'Group' 기능을 사용하지 않고 Runs를 그룹화할 수 있나요?
Group 버튼을 사용하여 수행할 수 있습니다.팀에서 어떻게 제거될 수 있나요?
팀에서 어떻게 제거될 수 있나요?
`wandb` 파일의 로컬 위치를 어떻게 정의할 수 있나요?
`wandb` 파일의 로컬 위치를 어떻게 정의할 수 있나요?
WANDB_DIR=<path>또는wandb.init(dir=<path>): 트레이닝 스크립트를 위해 생성된wandb폴더의 위치를 제어합니다. 기본값은./wandb입니다. 이 폴더에는 Run의 데이터와 로그가 저장됩니다.WANDB_ARTIFACT_DIR=<path>또는wandb.Artifact().download(root="<path>"): Artifacts가 다운로드되는 위치를 제어합니다. 기본값은./artifacts입니다.WANDB_CACHE_DIR=<path>:wandb.Artifact를 호출할 때 Artifacts가 생성되고 저장되는 위치입니다. 기본값은~/.cache/wandb입니다.WANDB_CONFIG_DIR=<path>: 구성 파일이 저장되는 위치입니다. 기본값은~/.config/wandb입니다.WANDB_DATA_DIR=<PATH>: 업로드 중 Artifacts 스테이징에 사용되는 위치를 제어합니다. 기본값은~/.cache/wandb-data/입니다.
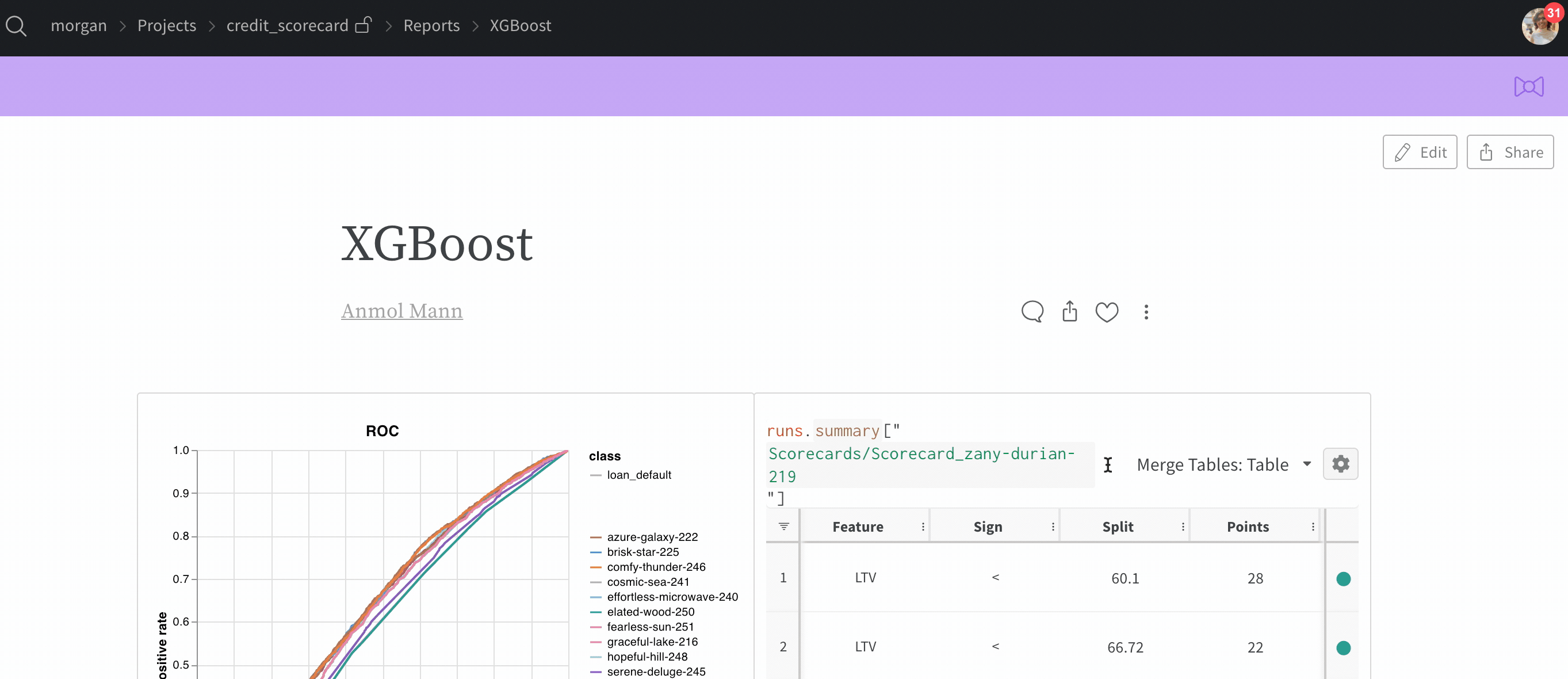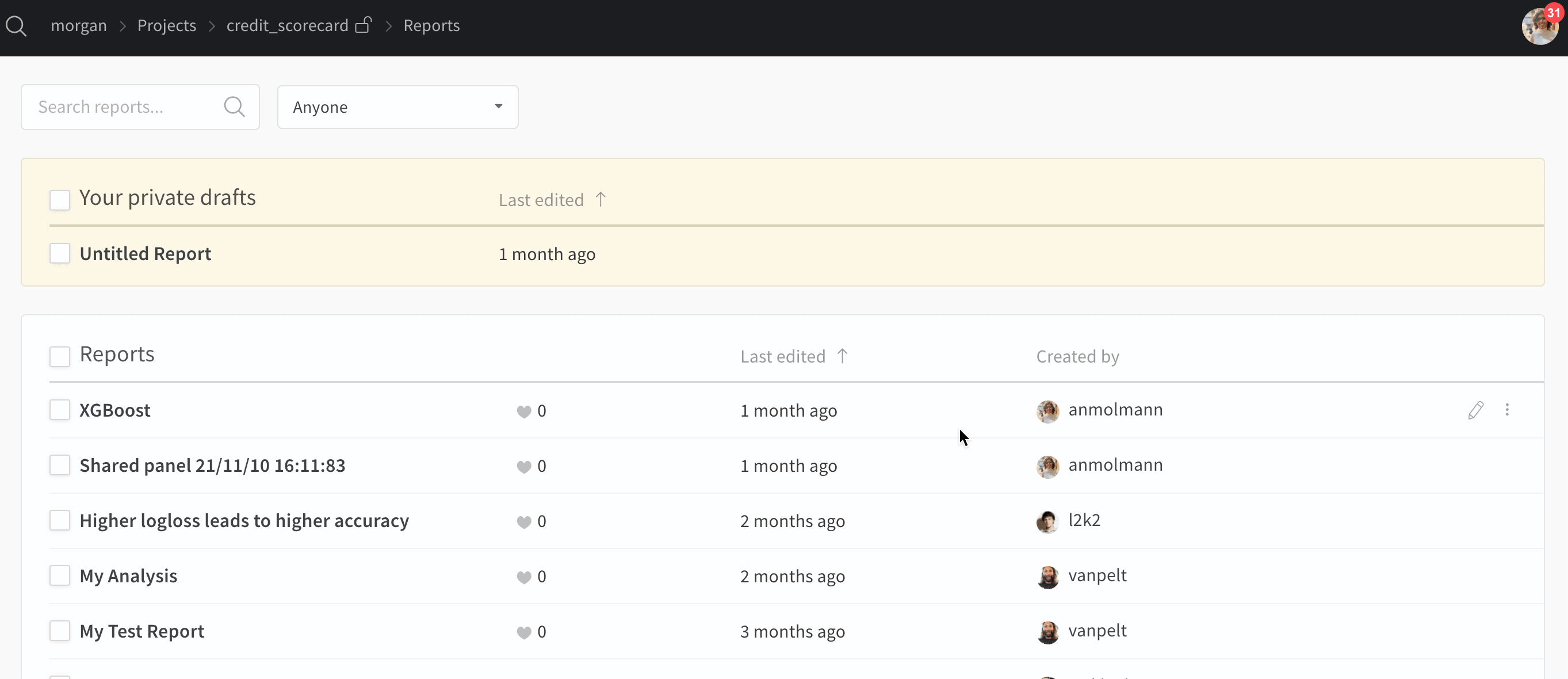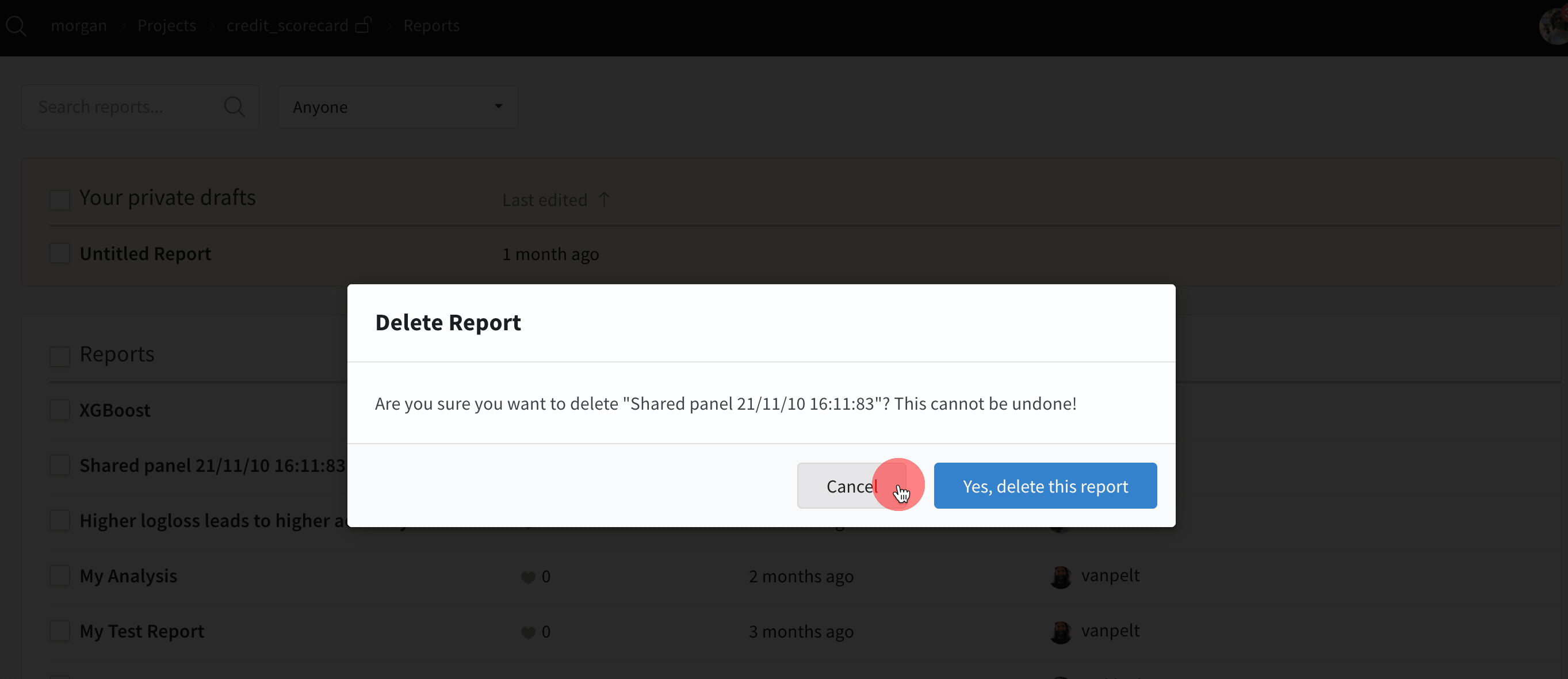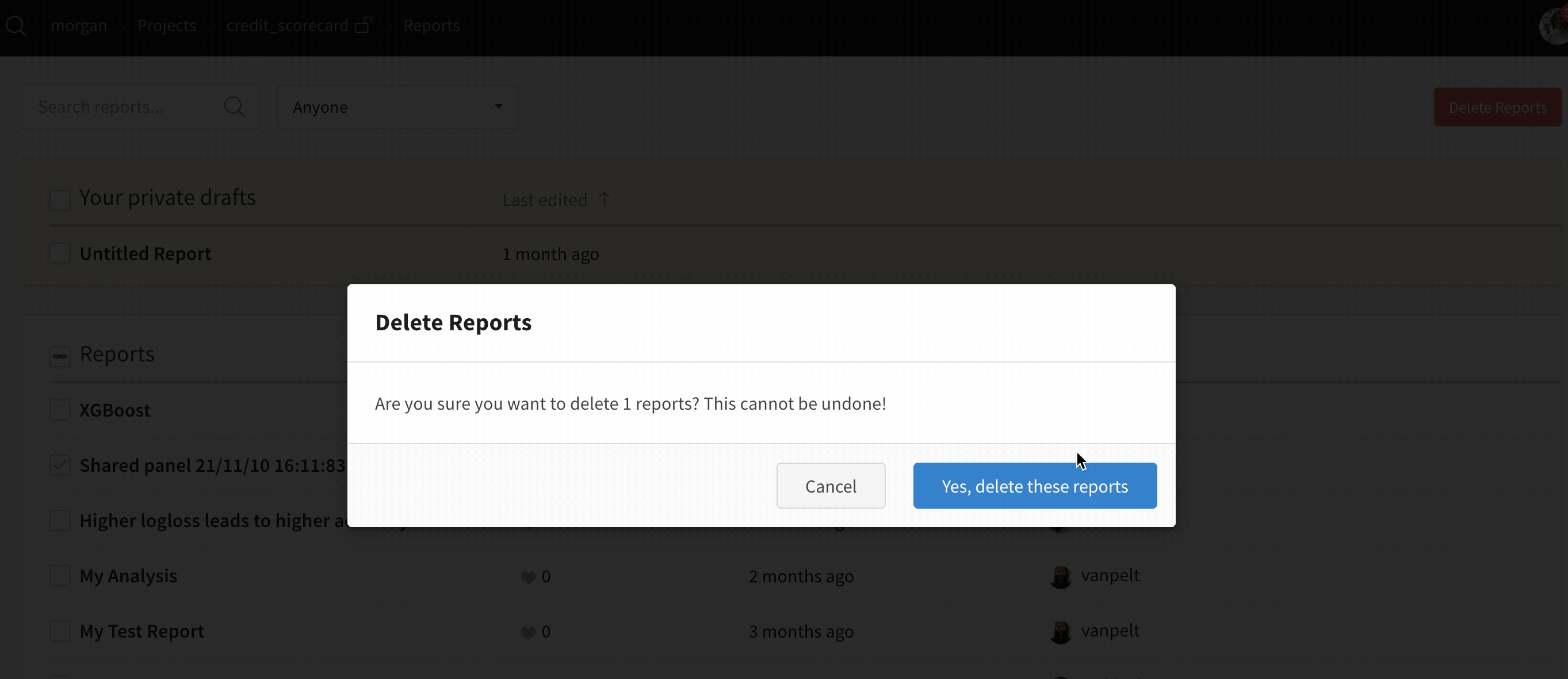
한 번에 하나씩이 아니라 여러 Runs를 대량으로 어떻게 삭제하나요?
한 번에 하나씩이 아니라 여러 Runs를 대량으로 어떻게 삭제하나요?
W&B Server에 어떻게 로그인하나요?
W&B Server에 어떻게 로그인하나요?
- 환경 변수
WANDB_BASE_URL을 Server URL로 설정합니다. wandb login의--host플래그를 Server URL로 설정합니다.
시스템 메트릭을 얼마나 자주 로그할지 변경할 수 있나요?
시스템 메트릭을 얼마나 자주 로그할지 변경할 수 있나요?
_stats_sampling_interval을 초 단위 숫자(float)로 설정하세요. 기본값은 10.0입니다.`AttributeError: module 'wandb' has no attribute ...`와 같은 오류는 어떻게 고치나요?
`AttributeError: module 'wandb' has no attribute ...`와 같은 오류는 어떻게 고치나요?
wandb를 임포트할 때 AttributeError: module 'wandb' has no attribute 'init' 또는 AttributeError: module 'wandb' has no attribute 'login'과 같은 오류가 발생하면, wandb가 설치되지 않았거나 설치가 손상되었지만 현재 작업 디렉토리에 wandb 디렉토리가 존재하는 경우입니다. 이 오류를 수정하려면 wandb를 언인스톨하고 해당 디렉토리를 삭제한 다음 wandb를 다시 설치하세요:Files 탭에 나타나지 않는 파일들은 어떻게 볼 수 있나요?
Files 탭에 나타나지 않는 파일들은 어떻게 볼 수 있나요?
`resume='must' but run (<run_id>) doesn't exist` 오류를 어떻게 해결하나요?
`resume='must' but run (<run_id>) doesn't exist` 오류를 어떻게 해결하나요?
resume='must' but run (<run_id>) doesn't exist 오류가 발생하면, 재개하려는 run이 프로젝트 또는 엔티티 내에 존재하지 않는 것입니다. 올바른 인스턴스에 로그인되어 있는지, 프로젝트와 엔티티가 설정되어 있는지 확인하세요:wandb login --relogin을 실행하여 인증되었는지 확인하세요.LaTeX 통합하기
LaTeX 통합하기
/를 누르고 인라인 수식 탭으로 이동하여 LaTeX 콘텐츠를 삽입하세요.W&B Inference에서 Invalid Authentication (401) 오류를 어떻게 해결하나요?
W&B Inference에서 Invalid Authentication (401) 오류를 어떻게 해결하나요?
API 키 확인
- 사용자 설정에서 새 API 키를 생성합니다.
- API 키를 안전하게 보관하세요.
프로젝트 구성 확인
프로젝트 형식이<your-team>/<your-project>로 올바르게 되어 있는지 확인하세요:Python 예시:흔한 실수들
- 팀 이름 대신 개인 엔티티 사용
- 팀 또는 프로젝트 이름 오타
- 팀과 프로젝트 사이의 슬래시(/) 누락
- 만료되거나 삭제된 API 키 사용
여전히 문제가 발생하나요?
- W&B 계정에 해당 팀과 프로젝트가 존재하는지 확인하세요
- 지정된 팀에 대한 엑세스 권한이 있는지 확인하세요
- 현재 API 키가 작동하지 않는다면 새 키를 생성해 보세요
W&B Inference 오류 처리를 위한 모범 사례는 무엇인가요?
W&B Inference 오류 처리를 위한 모범 사례는 무엇인가요?
1. 항상 오류 처리 구현
API 호출을 try-except 블록으로 감싸세요:2. 지수 백오프(exponential backoff)와 함께 재시도 로직 사용
3. 사용량 모니터링
- W&B Billing 페이지에서 크레딧 사용량을 추적하세요
- 한도에 도달하기 전에 알림을 설정하세요
- 애플리케이션에서 API 사용량을 로깅하세요
4. 특정 오류 코드 처리
5. 적절한 타임아웃 설정
사용 케이스에 맞게 합리적인 타임아웃을 구성하세요:추가 팁
- 디버깅을 위해 타임스탬프와 함께 오류를 로그하세요
- 더 나은 동시성 처리를 위해 비동기(async) 작업을 사용하세요
- 프로덕션 시스템을 위해 서킷 브레이커(circuit breakers)를 구현하세요
- API 호출을 줄이기 위해 적절한 경우 응답을 캐싱하세요
W&B Inference에서 왜 쿼터 부족 오류(402)가 발생하나요?
W&B Inference에서 왜 쿼터 부족 오류(402)가 발생하나요?
- W&B Billing 페이지에서 크레딧 잔액을 확인하세요
- 크레딧을 추가 구매하거나 플랜을 업그레이드하세요
- 지원팀에 한도 상향을 요청하세요
W&B Inference에서 왜 내 국가 또는 지역이 지원되지 않는다고 하나요?
W&B Inference에서 왜 내 국가 또는 지역이 지원되지 않는다고 하나요?
발생하는 이유
W&B Inference는 규정 준수 및 규제 요구 사항으로 인해 지리적 제한이 있습니다. 이 서비스는 지원되는 지리적 위치에서만 엑세스할 수 있습니다.할 수 있는 일
-
서비스 약관 확인
- 현재 지원되는 위치 리스트는 서비스 약관을 검토하세요
-
지원되는 위치에서 사용
- 지원되는 국가 또는 지역에 있을 때 서비스에 엑세스하세요
- 지원되는 위치에 있는 조직의 리소스를 사용하는 것을 고려해 보세요
-
어카운트 팀에 문의
- 엔터프라이즈 고객은 어카운트 익제큐티브와 옵션을 논의할 수 있습니다
- 일부 조직은 특별한 배치가 되어 있을 수 있습니다
오류 세부 정보
이 오류가 보일 때:W&B Inference에서 왜 속도 제한 오류(429)가 발생하나요?
W&B Inference에서 왜 속도 제한 오류(429)가 발생하나요?
- 병렬 요청 수를 줄이세요
- 요청 사이에 지연 시간을 추가하세요
- 지수 백오프를 구현하세요
- 참고: 속도 제한은 W&B 프로젝트별로 적용됩니다
속도 제한을 피하기 위한 모범 사례
-
지수 백오프와 함께 재시도 로직 구현:
- 병렬 요청 대신 배치 처리 사용
- W&B Billing 페이지에서 사용량 모니터링
기본 지출 캡(spending caps)
- Pro 계정: $6,000/월
- Enterprise 계정: $700,000/년
W&B Inference에서 서버 오류(500, 503)를 어떻게 해결하나요?
W&B Inference에서 서버 오류(500, 503)를 어떻게 해결하나요?
오류 유형
500 - Internal Server Error
메시지: “The server had an error while processing your request”이는 서버 측의 일시적인 내부 오류입니다.503 - Service Overloaded
메시지: “The engine is currently overloaded, please try again later”서비스에 트래픽이 몰리고 있습니다.서버 오류 처리 방법
-
재시도 전 대기
- 500 오류: 30-60초 대기
- 503 오류: 60-120초 대기
-
지수 백오프 사용
-
적절한 타임아웃 설정
- HTTP 클라이언트의 타임아웃 값을 늘리세요
- 더 나은 처리를 위해 비동기 작업을 고려하세요
지원팀에 문의해야 할 때
다음과 같은 경우 지원팀에 문의하세요:- 오류가 10분 이상 지속될 때
- 특정 시간에 반복되는 실패 패턴이 보일 때
- 오류 메시지에 추가 세부 정보가 포함되어 있을 때
- 오류 메시지와 코드
- 오류 발생 시간
- 코드 조각 (API 키는 제외)
- W&B 엔티티 및 프로젝트 이름
wandb에서 run 초기화 타임아웃 오류를 어떻게 해결하나요?
wandb에서 run 초기화 타임아웃 오류를 어떻게 해결하나요?
- 초기화 재시도: run 재시작을 시도합니다.
- 네트워크 연결 확인: 인터넷 연결이 안정적인지 확인합니다.
- wandb 버전 업데이트: 최신 버전의 wandb를 설치합니다.
- 타임아웃 설정 증가:
WANDB_INIT_TIMEOUT환경 변수를 수정합니다: - 디버깅 활성화: 상세 로그를 위해
WANDB_DEBUG=true및WANDB_CORE_DEBUG=true를 설정합니다. - 구성 확인: API 키와 프로젝트 설정이 올바른지 확인합니다.
- 로그 검토: 오류를 위해
debug.log,debug-internal.log,debug-core.log, 및output.log를 검사합니다.
InitStartError: Error communicating with wandb process
InitStartError: Error communicating with wandb process
- Linux 및 OS X
- Google Colab
테이블을 어떻게 삽입하나요?
테이블을 어떻게 삽입하나요?
gcc가 없는 환경에서 wandb Python 라이브러리를 어떻게 설치하나요?
gcc가 없는 환경에서 wandb Python 라이브러리를 어떻게 설치하나요?
wandb를 설치할 때 다음과 같은 오류가 발생하는 경우:psutil을 직접 설치하세요. https://pywharf.github.io/pywharf-pkg-repo/psutil에서 Python 버전과 운영 체제를 확인하세요.예를 들어, Linux의 Python 3.8에서 psutil을 설치하려면:psutil을 설치한 후, pip install wandb를 실행하여 wandb 설치를 완료하세요.W&B를 프로젝트에 인테그레이션하고 싶지만 이미지나 미디어를 업로드하고 싶지 않다면 어떻게 하나요?
W&B를 프로젝트에 인테그레이션하고 싶지만 이미지나 미디어를 업로드하고 싶지 않다면 어떻게 하나요?
모델 트레이닝 중에 인터넷 연결이 끊기면 어떻게 되나요?
모델 트레이닝 중에 인터넷 연결이 끊기면 어떻게 되나요?
WANDB_MODE=offline을 설정하세요. 이 구성은 메트릭을 하드 드라이브에 로컬로 저장합니다. 나중에 wandb sync DIRECTORY를 호출하여 데이터를 서버로 스트리밍하세요.W&B 팀에 어떻게 추가되나요?
W&B 팀에 어떻게 추가되나요?
- 팀 관리자나 관리 권한이 있는 사람에게 연락하여 초대를 요청하세요.
- 이메일에서 초대장을 확인하고 안내에 따라 팀에 합류하세요.
코드나 데이터셋 예시 없이 메트릭만 로그할 수 있나요?
코드나 데이터셋 예시 없이 메트릭만 로그할 수 있나요?
WANDB_DISABLE_CODE를true로 설정하여 모든 코드 추적을 끕니다. 이 작업은 git SHA 및 diff 패치의 수집을 방지합니다.WANDB_IGNORE_GLOBS를*.patch로 설정하여 diff 패치가 서버로 동기화되는 것을 중단하되,wandb restore와 함께 사용할 수 있도록 로컬에는 유지합니다.
https://wandb.ai/<team>/settings에서 팀 설정으로 이동합니다. 여기서<team>은 팀 이름입니다.- Privacy 섹션으로 스크롤합니다.
- Enable code saving by default를 토글하여 끕니다.
run 이름을 run ID로 설정할 수 있나요?
run 이름을 run ID로 설정할 수 있나요?
wandb로 작업을 어떻게 중단(kill)하나요?
wandb로 작업을 어떻게 중단(kill)하나요?
Ctrl+D를 누르세요.하나의 스크립트에서 여러 개의 Runs를 실행하려면 어떻게 해야 하나요?
하나의 스크립트에서 여러 개의 Runs를 실행하려면 어떻게 해야 하나요?
wandb.init()을 컨텍스트 매니저로 사용하는 것입니다. 이렇게 하면 run이 종료될 때 자동으로 마감되며, 스크립트에서 예외가 발생할 경우 실패로 표시됩니다:run.finish()를 명시적으로 호출할 수도 있습니다:동시에 여러 개의 run 활성화
wandb 0.19.10부터는reinit 설정을 "create_new"로 지정하여 동시에 여러 개의 활성 run을 생성할 수 있습니다.reinit="create_new"에 대한 자세한 정보는 프로세스당 여러 run 실행을 참조하세요.로컬 인스턴스에서 문제가 발생했을 때 어떤 파일을 확인해야 하나요?
로컬 인스턴스에서 문제가 발생했을 때 어떤 파일을 확인해야 하나요?
Debug Bundle을 확인하세요. 관리자는 /system-admin 페이지에서 오른쪽 상단의 W&B 아이콘을 선택한 다음 Debug Bundle을 선택하여 이를 가져올 수 있습니다.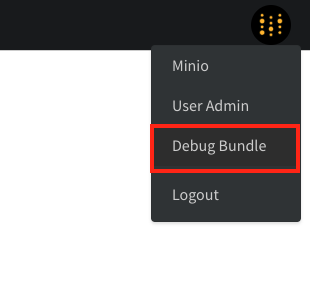
run이 완료된 후 추가 메트릭을 어떻게 로그할 수 있나요?
run이 완료된 후 추가 메트릭을 어떻게 로그할 수 있나요?
wandb.init()의 그룹 파라미터를 단일 실험 내의 모든 프로세스에 대해 고유한 값으로 설정하세요. Runs 탭이 그룹 ID별로 테이블을 묶어 시각화가 제대로 작동하도록 보장합니다. 이 접근 방식은 동시 실험과 트레이닝 Runs를 한 곳에서 결과를 로그하면서 가능하게 합니다.더 간단한 워크플로우의 경우, resume=True 및 id=UNIQUE_ID와 함께 wandb.init()을 호출한 다음, 동일한 id=UNIQUE_ID로 다시 wandb.init()을 호출하세요. run.log() 또는 run.summary()를 사용하여 정상적으로 로그하면 run 값이 그에 따라 업데이트됩니다.기존 run에 Artifact를 어떻게 로그하나요?
기존 run에 Artifact를 어떻게 로그하나요?
지속적 통합(CI)이나 내부 툴에서 실행된 Runs를 어떻게 로그하나요?
지속적 통합(CI)이나 내부 툴에서 실행된 Runs를 어떻게 로그하나요?
WANDB_USERNAME 또는 WANDB_USER_EMAIL 환경 변수를 설정하세요.
값의 리스트(list of values)를 어떻게 로그하나요?
값의 리스트(list of values)를 어떻게 로그하나요?
wandb.Run.log()를 사용하여 손실값(losses)을 로그하는 두 가지 다른 방법을 보여줍니다.- 사전(dictionary) 사용
- 히스토그램으로 로그
최종 평가 정확도와 같이 시간이 지나도 변하지 않는 메트릭을 어떻게 로그하나요?
최종 평가 정확도와 같이 시간이 지나도 변하지 않는 메트릭을 어떻게 로그하나요?
run.log({'final_accuracy': 0.9})를 사용하면 최종 정확도가 올바르게 업데이트됩니다. 기본적으로 run.log({'final_accuracy': <value>})는 run.settings['final_accuracy']를 업데이트하며, 이는 runs 테이블의 값을 반영합니다.일부 메트릭은 배수(batches)마다 로그하고 일부는 에포크(epochs)마다만 로그하고 싶다면 어떻게 하나요?
일부 메트릭은 배수(batches)마다 로그하고 일부는 에포크(epochs)마다만 로그하고 싶다면 어떻게 하나요?
두 개의 다른 시간 척도(time scales)로 메트릭을 로그할 수 있나요?
두 개의 다른 시간 척도(time scales)로 메트릭을 로그할 수 있나요?
batch 및 epoch 같은 인덱스를 로그하세요. 한 단계에서는 wandb.Run.log()({'train_accuracy': 0.9, 'batch': 200})를 사용하고 다른 단계에서는 wandb.Run.log()({'val_accuracy': 0.8, 'epoch': 4})를 사용하세요. UI에서 각 차트의 x축으로 원하는 값을 설정하세요. 특정 인덱스를 기본 x축으로 설정하려면 Run.define_metric()을 사용하세요. 제공된 예시의 경우 다음 코드를 사용합니다:수백만 단계를 W&B에 로그하면 어떻게 되나요? 브라우저에서는 어떻게 렌더링되나요?
수백만 단계를 W&B에 로그하면 어떻게 되나요? 브라우저에서는 어떻게 렌더링되나요?
팀 엔티티 대신 개인 엔티티로 로그해야 하는 경우는 언제인가요?
팀 엔티티 대신 개인 엔티티로 로그해야 하는 경우는 언제인가요?
공유 머신에서 올바른 wandb 사용자에게 로그를 남기려면 어떻게 하나요?
공유 머신에서 올바른 wandb 사용자에게 로그를 남기려면 어떻게 하나요?
WANDB_API_KEY 환경 변수를 설정하여 Runs가 올바른 WandB 계정으로 로그되도록 하세요. 환경에서 소스화된 경우, 이 변수는 로그인 시 올바른 자격 증명을 제공합니다. 또는 스크립트에서 환경 변수를 직접 설정하세요.X를 API 키로 바꾸어 export WANDB_API_KEY=X 커맨드를 실행하세요. API 키는 wandb.ai/settings에서 생성할 수 있습니다.로깅이 내 트레이닝을 방해하나요?
로깅이 내 트레이닝을 방해하나요?
wandb.log 함수는 로컬 파일에 한 줄을 작성하며 네트워크 호출을 방해하지 않습니다. wandb.init을 호출할 때 동일한 머신에서 새로운 프로세스가 시작됩니다. 이 프로세스는 파일 시스템의 변경 사항을 수신 대기하고 웹 서비스와 비동기적으로 통신하므로 로컬 작업이 중단 없이 계속될 수 있습니다.로깅을 어떻게 끄나요?
로깅을 어떻게 끄나요?
wandb offline 커맨드는 환경 변수 WANDB_MODE=offline을 설정하여 데이터가 원격 W&B 서버와 동기화되는 것을 방지합니다. 이 작업은 모든 프로젝트에 영향을 미쳐 W&B 서버로의 데이터 로깅을 중단합니다.경고 메시지를 억제하려면 다음 코드를 사용하세요:왜 특정 문자가 포함된 메트릭으로 정렬하거나 필터링할 수 없나요?
왜 특정 문자가 포함된 메트릭으로 정렬하거나 필터링할 수 없나요?
유효한 메트릭 이름
- 허용되는 문자: 영문자 (A-Z, a-z), 숫자 (0-9), 밑줄 (_)
- 시작 문자: 이름은 영문자나 밑줄로 시작해야 함
- 패턴: 메트릭 이름은
/^[_a-zA-Z][_a-zA-Z0-9]*$/와 일치해야 함
예시
유효한 메트릭 이름:권장 해결책
유효하지 않은 문자를 밑줄 같은 유효한 문자로 바꾸세요:"test acc"대신"test_acc"사용"loss-train"대신"loss_train"사용"acc,val"대신"acc_val"사용
Teams 플랜에 월간 구독 옵션이 있나요?
Teams 플랜에 월간 구독 옵션이 있나요?
run을 한 프로젝트에서 다른 프로젝트로 옮길 수 있나요?
run을 한 프로젝트에서 다른 프로젝트로 옮길 수 있나요?
- 이동할 run이 있는 프로젝트 페이지로 이동합니다.
- Runs 탭을 클릭하여 runs 테이블을 엽니다.
- 이동할 Runs를 선택합니다.
- Move 버튼을 클릭합니다.
- 대상 프로젝트를 선택하고 작업을 확인합니다.
wandb artifact get SDK 커맨드나 Api.artifact API를 사용하여 Artifact를 다운로드한 후, wandb artifact put 또는 Api.artifact API를 사용하여 run의 새 위치로 업로드할 수 있습니다.서로 다른 Runs가 선택된 여러 차트를 어떻게 가져오나요?
서로 다른 Runs가 선택된 여러 차트를 어떻게 가져오나요?
- 여러 개의 패널 그리드를 생성합니다.
- 각 패널 그리드에 대해 원하는 run 세트를 선택하기 위해 필터를 적용합니다.
- 패널 그리드 내에 원하는 차트를 생성합니다.
분산 트레이닝처럼 멀티프로세싱에서 wandb를 어떻게 사용하나요?
분산 트레이닝처럼 멀티프로세싱에서 wandb를 어떻게 사용하나요?
wandb.init()이 없는 프로세스에서 wandb 메소드를 호출하지 않도록 프로그램을 구성하세요.다음 접근 방식들을 사용하여 멀티프로세스 트레이닝을 관리하세요:- 모든 프로세스에서
wandb.init을 호출하고 group 키워드 인수를 사용하여 공유 그룹을 생성합니다. 각 프로세스는 자체 wandb run을 가지며 UI는 트레이닝 프로세스들을 함께 그룹화합니다. - 하나의 프로세스에서만
wandb.init을 호출하고 멀티프로세싱 큐를 통해 로그할 데이터를 전달합니다.
W&B는 `multiprocessing` 라이브러리를 사용하나요?
W&B는 `multiprocessing` 라이브러리를 사용하나요?
multiprocessing 라이브러리를 사용합니다. 다음과 같은 오류 메시지는 잠재적인 문제를 나타냅니다:if __name__ == "__main__":으로 엔트리 포인트 보호를 추가하세요. 이 보호 조치는 스크립트에서 직접 W&B를 실행할 때 필수적입니다.W&B Sweep의 일부로 모든 하이퍼파라미터 값을 제공해야 하나요? 기본값을 설정할 수 있나요?
W&B Sweep의 일부로 모든 하이퍼파라미터 값을 제공해야 하나요? 기본값을 설정할 수 있나요?
(run.config())를 사용하여 Sweep 구성에서 하이퍼파라미터 이름과 값에 엑세스하세요.Sweep 외부의 Runs의 경우, wandb.init()의 config 인수에 사전을 전달하여 wandb.Run.config() 값을 설정하세요. Sweep에서는 wandb.init()에 제공된 모든 구성이 기본값 역할을 하며, Sweep이 이를 덮어쓸 수 있습니다.명시적인 행동을 위해 run.config.setdefaults()를 사용하세요. 다음 코드 조각은 두 가지 방법을 모두 보여줍니다:- wandb.init()
- config.setdefaults()
여러 메트릭 최적화하기
여러 메트릭 최적화하기
W&B UI에서 로그된 차트와 미디어를 어떻게 정리할 수 있나요?
W&B UI에서 로그된 차트와 미디어를 어떻게 정리할 수 있나요?
/ 문자를 사용합니다. 기본적으로 로그된 아이템 이름에서 / 앞의 세그먼트가 “Panel Section”이라고 불리는 패널 그룹을 정의합니다./로 구분된 모든 세그먼트를 기준으로 패널 그룹화를 조정할 수 있습니다.'overflows maximum values of a signed 64 bits integer' 오류를 어떻게 해결하나요?
'overflows maximum values of a signed 64 bits integer' 오류를 어떻게 해결하나요?
?workspace=clear를 추가하고 Enter를 누르세요. 이 작업은 프로젝트 페이지 워크스페이스의 클리어된 버전으로 안내합니다.클래스 속성(class attribute)을 wandb.Run.log()에 전달하면 어떻게 되나요?
클래스 속성(class attribute)을 wandb.Run.log()에 전달하면 어떻게 되나요?
wandb.Run.log()에 전달하는 것을 피하세요. 네트워크 호출이 실행되기 전에 속성이 변경될 수 있습니다. 메트릭을 클래스 속성으로 저장할 때는 wandb.Run.log() 호출 시점의 속성값과 로그된 메트릭이 일치하도록 딥 카피(deep copy)를 사용하세요.단계별로 플로팅하는 대신 메트릭의 최대값을 플로팅할 수 있나요?
단계별로 플로팅하는 대신 메트릭의 최대값을 플로팅할 수 있나요?
내 프로젝트의 공개 범위를 어떻게 변경할 수 있나요?
내 프로젝트의 공개 범위를 어떻게 변경할 수 있나요?
- W&B 앱에서 프로젝트의 아무 페이지에서나 왼쪽 내비게이션의 Overview를 클릭합니다.
- 오른쪽 상단에서 Edit을 클릭합니다.
-
Project visibility에 대해 새로운 값을 선택합니다:
- Team (기본값): 팀원만 프로젝트를 보고 편집할 수 있습니다.
- Restricted: 초대된 멤버만 프로젝트에 엑세스할 수 있으며 퍼블릭 엑세스는 차단됩니다.
- Open: 누구나 Runs를 제출하거나 Reports를 생성할 수 있지만 편집은 팀원만 가능합니다. 강의 환경, 공개 벤치마크 경진대회 또는 기타 비영구적인 맥락에만 적합합니다.
-
Public: 누구나 프로젝트를 볼 수 있지만 편집은 팀원만 가능합니다.
W&B 관리자가 Public 공개 범위를 비활성화한 경우 선택할 수 없습니다. 대신 보기 전용 W&B Report를 공유하거나 W&B 조직 관리자에게 도움을 요청하세요.
- Save를 클릭합니다.
'Failed to query for notebook' 오류를 어떻게 처리하나요?
'Failed to query for notebook' 오류를 어떻게 처리하나요?
"Failed to query for notebook name, you can set it manually with the WANDB_NOTEBOOK_NAME environment variable,"라는 오류 메시지가 발생하면 환경 변수를 설정하여 해결하세요. 여러 가지 방법으로 이를 수행할 수 있습니다:- Notebook
- Python
내 스크립트에서 랜덤하게 생성된 run 이름을 어떻게 가져오나요?
내 스크립트에서 랜덤하게 생성된 run 이름을 어떻게 가져오나요?
.save() 메소드를 호출하세요. run 오브젝트의 name 속성을 사용하여 이름을 가져옵니다.run과 함께 삭제된 Artifact를 복구할 수 있나요?
run과 함께 삭제된 Artifact를 복구할 수 있나요?
삭제된 Runs를 어떻게 복구하나요?
삭제된 Runs를 어떻게 복구하나요?
- Project Overview 페이지로 이동합니다.
- 오른쪽 상단의 점 세 개를 클릭합니다.
- Undelete recently deleted runs를 선택합니다.
- 최근 7일 이내에 삭제된 Runs만 복구할 수 있습니다.
- 복구가 옵션이 아닌 경우 W&B API를 사용하여 로그를 수동으로 업로드할 수 있습니다.
데이터 새로고침
데이터 새로고침
비밀번호 재설정 이메일을 받을 수 없는 경우 계정 엑세스를 어떻게 되찾나요?
비밀번호 재설정 이메일을 받을 수 없는 경우 계정 엑세스를 어떻게 되찾나요?
- 스팸 또는 정크 폴더 확인: 이메일이 필터링되지 않았는지 확인하세요.
- 이메일 확인: 계정과 연결된 이메일이 정확한지 확인하세요.
- SSO 옵션 확인: 사용 가능하다면 “Sign in with Google” 같은 서비스를 사용해 보세요.
- 지원팀 문의: 문제가 지속되면 사용자 이름과 이메일을 포함하여 지원팀 (support@wandb.com)에 도움을 요청하세요.
관리자 권한 없이 팀 공간에서 프로젝트를 어떻게 제거할 수 있나요?
관리자 권한 없이 팀 공간에서 프로젝트를 어떻게 제거할 수 있나요?
- 현재 관리자에게 프로젝트 제거를 요청하세요.
- 관리자에게 프로젝트 관리를 위한 임시 엑세스 권한 부여를 요청하세요.
프로젝트 이름을 어떻게 변경하나요?
프로젝트 이름을 어떻게 변경하나요?
- Project overview로 이동합니다.
- Edit Project를 클릭합니다.
model-registry와 같이 보호된 프로젝트 이름은 변경할 수 없습니다. 보호된 이름에 대한 도움이 필요하면 지원팀에 문의하세요.
만료된 라이선스를 어떻게 갱신하나요?
만료된 라이선스를 어떻게 갱신하나요?
Markdown에서 변환한 후 Report의 모습이 달라졌습니다.
Markdown에서 변환한 후 Report의 모습이 달라졌습니다.
WYSIWYG으로 변경한 후 Report 실행 속도가 느려졌습니다
WYSIWYG으로 변경한 후 Report 실행 속도가 느려졌습니다
Report에서 Markdown을 사용할 수 있나요?
Report에서 Markdown을 사용할 수 있나요?
W&B 계정의 완전한 삭제를 어떻게 요청하나요?
W&B 계정의 완전한 삭제를 어떻게 요청하나요?
그리드 검색(grid search)을 재실행할 수 있나요?
그리드 검색(grid search)을 재실행할 수 있나요?
내 계정의 로그인 문제를 어떻게 해결할 수 있나요?
내 계정의 로그인 문제를 어떻게 해결할 수 있나요?
- 엑세스 확인: 올바른 이메일이나 사용자 이름을 사용하고 있는지 확인하고 관련 팀이나 프로젝트의 멤버십을 확인하세요.
- 브라우저 트러블슈팅:
- 캐시 데이터 간섭을 피하기 위해 시크릿 창을 사용하세요.
- 브라우저 캐시를 지우세요.
- 다른 브라우저나 기기에서 로그인을 시도하세요.
- SSO 및 권한:
- ID 제공업체(IdP) 및 Single Sign-On (SSO) 설정을 확인하세요.
- SSO를 사용하는 경우 적절한 SSO 그룹에 포함되어 있는지 확인하세요.
- 기술적 문제:
- 추가 트러블슈팅을 위해 특정 오류 메시지를 기록해 두세요.
- 문제가 지속되면 추가 지원을 위해 지원팀에 연락하세요.
run을 로그할 때 발생하는 권한 오류를 어떻게 해결하나요?
run을 로그할 때 발생하는 권한 오류를 어떻게 해결하나요?
- 엔티티 및 프로젝트 이름 확인: 코드에서 W&B 엔티티와 프로젝트 이름의 철자와 대소문자 구분이 정확한지 확인하세요.
- 권한 확인: 관리자에 의해 필요한 권한이 부여되었는지 확인하세요.
- 로그인 자격 증명 확인: 올바른 W&B 계정에 로그인했는지 확인하세요. 다음 코드로 run을 생성하여 테스트해 보세요:
- API 키 설정:
WANDB_API_KEY환경 변수를 사용하세요: - 호스트 정보 확인: 커스텀 배포의 경우 호스트 URL을 설정하세요:
W&B에서 run을 재개할 때 resume 파라미터를 어떻게 사용하나요?
W&B에서 run을 재개할 때 resume 파라미터를 어떻게 사용하나요?
resume 파라미터를 사용하려면 entity, project, id가 지정된 wandb.init()에서 resume 인수를 설정하세요. resume 인수는 "must" 또는 "allow" 값을 받습니다.Python 코드를 사용하여 Sweep을 어떻게 재개하나요?
Python 코드를 사용하여 Sweep을 어떻게 재개하나요?
sweep_id를 wandb.agent() 함수에 전달하세요.Artifact에 보존 또는 만료 정책을 어떻게 설정하나요?
Artifact에 보존 또는 만료 정책을 어떻게 설정하나요?
엑세스를 어떻게 로테이트(rotate)하거나 해지하나요?
엑세스를 어떻게 로테이트(rotate)하거나 해지하나요?
'Run Finished' 알림이 노트북에서 작동하나요?
'Run Finished' 알림이 노트북에서 작동하나요?
run.alert()를 사용하세요.로컬에서는 트레이닝이 잘 되는데 W&B UI에서는 왜 run이 crashed로 표시되나요?
로컬에서는 트레이닝이 잘 되는데 W&B UI에서는 왜 run이 crashed로 표시되나요?
계정이 없는 사람이 run 결과를 어떻게 볼 수 있나요?
계정이 없는 사람이 run 결과를 어떻게 볼 수 있나요?
anonymous="allow"로 스크립트를 실행하면:- 임시 계정 자동 생성: W&B는 로그인된 계정이 있는지 확인합니다. 계정이 없으면 W&B는 새로운 익명 계정을 생성하고 해당 세션의 API 키를 저장합니다.
- 빠른 결과 로깅: Users는 반복적으로 스크립트를 실행하고 W&B 대시보드에서 즉시 결과를 볼 수 있습니다. 이러한 소유권이 주장되지 않은 익명 Runs는 7일 동안 유지됩니다.
- 유용할 때 데이터 소유권 주장: 사용자가 W&B에서 가치 있는 결과를 식별하면, 페이지 상단의 배너에 있는 버튼을 클릭하여 해당 run 데이터를 실제 계정에 저장할 수 있습니다. 소유권을 주장하지 않으면 run 데이터는 7일 후 삭제됩니다.
SLURM에서 Sweeps를 어떻게 실행해야 하나요?
SLURM에서 Sweeps를 어떻게 실행해야 하나요?
wandb agent --count 1 SWEEP_ID를 실행하세요. 이 커맨드는 단일 트레이닝 작업을 실행한 후 종료되므로, 하이퍼파라미터 검색의 병렬성을 활용하면서 리소스 요청을 위한 런타임 예측을 용이하게 합니다.오프라인에서 wandb를 실행할 수 있나요?
오프라인에서 wandb를 실행할 수 있나요?
- 인터넷 연결 없이 메트릭을 로컬에 저장하려면 환경 변수
WANDB_MODE=offline을 설정하세요. - 업로드할 준비가 되면 디렉토리에서
wandb init을 실행하여 프로젝트 이름을 설정합니다. wandb sync YOUR_RUN_DIRECTORY를 사용하여 메트릭을 클라우드 서비스로 전송하고 호스팅된 웹 앱에서 결과에 엑세스하세요.
wandb.init() 실행 후 run.settings._offline 또는 run.settings.mode를 확인하세요.프로젝트당 몇 개의 Runs를 생성할 수 있나요?
프로젝트당 몇 개의 Runs를 생성할 수 있나요?
내 run의 상태가 UI에서는 `crashed`이지만 내 머신에서는 여전히 실행 중입니다. 내 데이터를 어떻게 되찾나요?
내 run의 상태가 UI에서는 `crashed`이지만 내 머신에서는 여전히 실행 중입니다. 내 데이터를 어떻게 되찾나요?
wandb sync [PATH_TO_RUN]를 실행하여 데이터를 복구하세요. run의 경로는 wandb 디렉토리 내에서 진행 중인 run의 Run ID와 일치하는 폴더입니다.왜 동일한 메트릭이 두 번 이상 나타나나요?
왜 동일한 메트릭이 두 번 이상 나타나나요?
number, string, bool, other (주로 배열), 그리고 Histogram이나 Image 같은 wandb 데이터 유형입니다. 이 문제를 방지하려면 키당 하나의 유형만 보내세요.메트릭 이름은 대소문자를 구분하지 않습니다. "My-Metric"과 "my-metric"처럼 대소문자만 다른 이름의 사용을 피하세요.코드를 어떻게 저장하나요?
코드를 어떻게 저장하나요?
wandb.init에서 save_code=True를 사용하여 run을 실행하는 메인 스크립트나 노트북을 저장하세요. run의 모든 코드를 저장하려면 Artifacts를 사용하여 코드 버전을 관리하세요. 다음 예시는 이 프로세스를 보여줍니다:내 run과 관련된 git commit을 어떻게 저장할 수 있나요?
내 run과 관련된 git commit을 어떻게 저장할 수 있나요?
wandb.init이 호출되면 시스템은 원격 리포지토리 링크와 최신 커밋의 SHA를 포함한 git 정보를 자동으로 수집합니다. 이 정보는 run 페이지에 나타납니다. 이 정보를 보려면 스크립트를 실행할 때의 현재 작업 디렉토리가 git으로 관리되는 폴더 내에 있어야 합니다.사용자에게는 git 커밋과 실험 실행에 사용된 커맨드가 계속 보이지만, 외부 사용자에게는 숨겨집니다. 퍼블릭 프로젝트에서도 이러한 세부 정보는 프라이빗하게 유지됩니다.메트릭을 오프라인으로 저장하고 나중에 W&B에 동기화할 수 있나요?
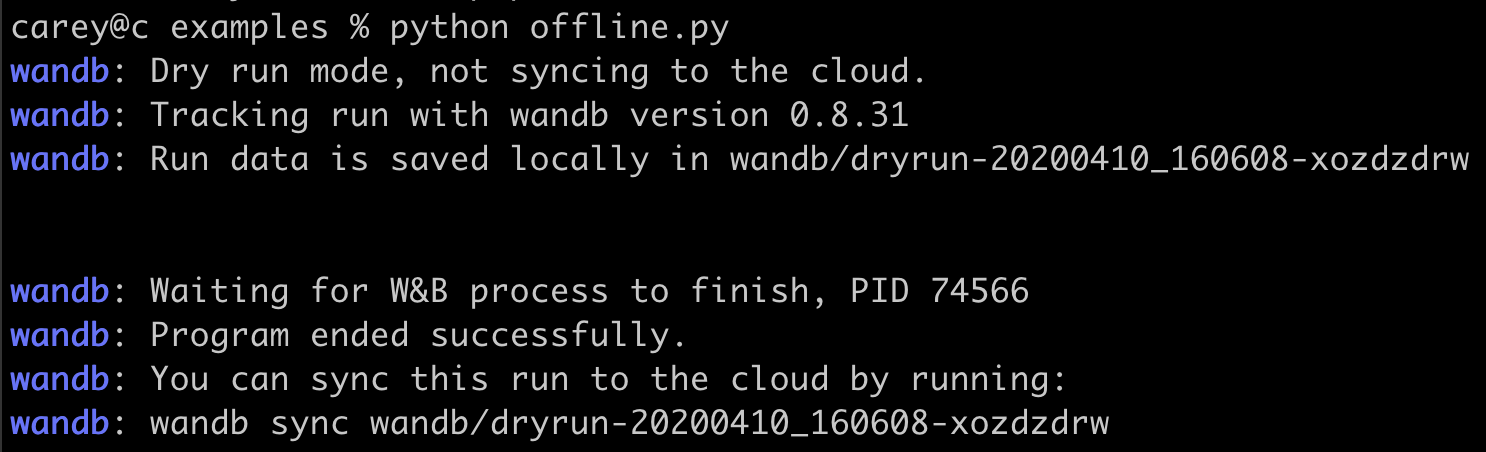
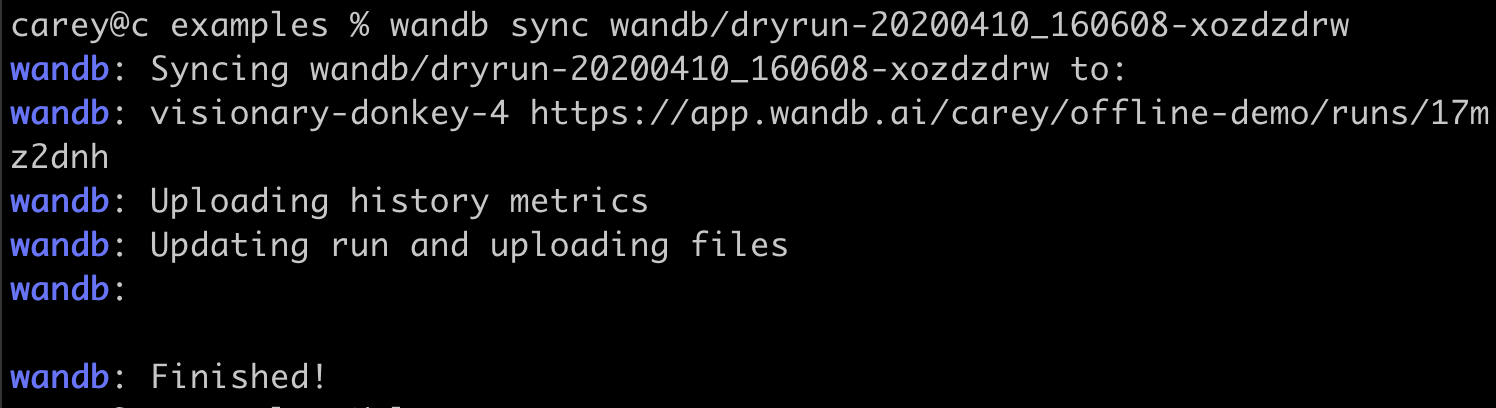
메트릭을 오프라인으로 저장하고 나중에 W&B에 동기화할 수 있나요?
wandb.init은 메트릭을 클라우드에 실시간으로 동기화하는 프로세스를 시작합니다. 오프라인 사용을 위해 두 개의 환경 변수를 설정하여 오프라인 모드를 활성화하고 나중에 동기화하세요.다음 환경 변수를 설정하세요:WANDB_API_KEY=$KEY, 여기서$KEY는 사용자 설정에서 생성된 API 키입니다.WANDB_MODE="offline".
우리 조직의 저장된 바이트, 추적된 바이트 및 추적된 시간을 어떻게 확인할 수 있나요?
우리 조직의 저장된 바이트, 추적된 바이트 및 추적된 시간을 어떻게 확인할 수 있나요?
https://wandb.ai/account-settings/<organization-name>/settings에서 조직 설정으로 이동합니다.- Billing 탭을 선택합니다.
- Usage this billing period 섹션 내에서 View usage 버튼을 선택합니다.
<>로 둘러싸인 값들을 조직 이름으로 바꾸어 입력하세요.왜 내가 로그한 것보다 데이터 포인트가 적게 보이나요?
왜 내가 로그한 것보다 데이터 포인트가 적게 보이나요?
Step이 아닌 다른 X축에 대해 메트릭을 시각화할 때 더 적은 데이터 포인트가 보일 수 있습니다. 메트릭이 동기화 상태를 유지하려면 동일한 Step에서 로그되어야 합니다. 동일한 Step에서 로그된 메트릭만 샘플 간 보간 중에 샘플링됩니다.가이드라인메트릭을 단일 log() 호출로 묶으세요. 예를 들어 다음과 같이 하는 대신:log() 호출에서 step 값이 동일해야 메트릭이 동일한 스텝 아래에 기록되고 함께 샘플링됩니다. step 값은 각 호출에서 단조롭게 증가해야 합니다. 그렇지 않으면 step 값은 무시됩니다.Microsoft Teams로 run 알림을 어떻게 보내나요?
Microsoft Teams로 run 알림을 어떻게 보내나요?
- Teams 채널의 이메일 주소를 설정합니다. 알림을 받고 싶은 Teams 채널의 이메일 주소를 생성합니다.
- W&B 알림 이메일을 Teams 채널의 이메일 주소로 포워딩합니다. W&B가 이메일로 알림을 보내도록 구성한 다음, 이 이메일들을 Teams 채널 이메일로 포워딩하세요.
서비스 계정이란 무엇이며 왜 유용한가요?
서비스 계정이란 무엇이며 왜 유용한가요?
- 라이선스 미소비: 서비스 계정은 사용자 시트나 라이선스를 소비하지 않습니다
- 전용 API 키: 자동화된 워크플로우를 위한 보안 자격 증명
- 사용자 귀속: 선택적으로 자동화된 Runs를 실제 사용자에게 귀속 가능
- 엔터프라이즈급: 대규모 프로덕션 자동화를 위해 구축됨
- 위임된 작업: 서비스 계정은 해당 계정을 생성한 사용자나 조직을 대신하여 작동합니다
WANDB_USERNAME 또는 WANDB_USER_EMAIL을 사용하여 이러한 기계 실행 run 중 하나에 사용자 이름을 연결할 수 있습니다.모범 사례와 상세 설정 지침을 포함한 서비스 계정에 대한 종합적인 정보는 서비스 계정을 사용한 워크플로우 자동화를 참조하세요. 팀 문맥에서 서비스 계정이 어떻게 작동하는지에 대한 정보는 팀 서비스 계정 행동을 참조하세요.To create a new team-scoped service account and API key:- In your team’s settings, click Service Accounts.
- Click New Team Service Account.
- Provide a name for the service account.
- Set Authentication Method to Generate API key (default). If you select Federated Identity, the service account cannot own API keys.
- Click Create.
- Find the service account you just created.
- Click the action menu (
...), then click Create API key. - Provide a name for the API key, then click Create.
- Copy the API key and store it securely.
- Click Done.
커스텀 차트에서 'step slider'를 어떻게 표시하나요?
커스텀 차트에서 'step slider'를 어떻게 표시하나요?
summaryTable 대신 historyTable을 사용하도록 변경하면 커스텀 차트 에디터에서 “Show step selector” 옵션이 제공됩니다. 이 기능에는 스텝 선택을 위한 슬라이더가 포함됩니다.W&B 안내 메시지를 어떻게 조용하게 만드나요?
W&B 안내 메시지를 어떻게 조용하게 만드나요?
logging.ERROR로 설정하여 오류만 표시하고 안내(info) 레벨의 로그 출력은 억제하세요.WANDB_QUIET 환경 변수를 True로 설정하세요. 로그 출력을 완전히 끄려면 WANDB_SILENT 환경 변수를 True로 설정하세요. 노트북에서는 wandb.login을 실행하기 전에 WANDB_QUIET 또는 WANDB_SILENT를 설정하세요:- Notebook
- Python
wandb가 내 트레이닝 속도를 늦추나요?
wandb가 내 트레이닝 속도를 늦추나요?
W&B는 멀티 테넌트(Multi-tenant)를 위한 SSO를 지원하나요?
W&B는 멀티 테넌트(Multi-tenant)를 위한 SSO를 지원하나요?
- ID 제공업체에서 싱글 페이지 애플리케이션 (SPA)을 생성합니다.
grant_type을implicit플로우로 설정합니다.- 콜백 URI를
https://wandb.auth0.com/login/callback으로 설정합니다.
Client ID와 Issuer URL을 고객 성공 매니저 (CSM)에게 전달하세요. W&B는 이 세부 정보를 사용하여 Auth0 연결을 구축하고 SSO를 활성화할 것입니다.wandb가 내 터미널이나 주피터 노트북 출력에 기록하는 것을 어떻게 중단시키나요?
wandb가 내 터미널이나 주피터 노트북 출력에 기록하는 것을 어떻게 중단시키나요?
WANDB_SILENT를 true로 설정하세요.- Python
- Notebook
- Command-Line
Runs를 삭제한 후에도 왜 스토리지 미터가 업데이트되지 않나요?
Runs를 삭제한 후에도 왜 스토리지 미터가 업데이트되지 않나요?
- 스토리지 미터는 처리 지연으로 인해 Runs를 삭제한 즉시 업데이트되지 않습니다.
- 백엔드 시스템이 사용량 변화를 정확하게 동기화하고 반영하는 데 시간이 필요합니다.
- 스토리지 미터가 업데이트되지 않았다면 변경 사항이 처리될 때까지 기다려 주세요.
wandb는 로그를 어떻게 스트리밍하고 디스크에 기록하나요?
wandb는 로그를 어떻게 스트리밍하고 디스크에 기록하나요?
WANDB_MODE=offline 구성을 지원하기 위해 이벤트를 메모리에 큐잉하고 비동기적으로 디스크에 기록하여 로깅 후 동기화를 가능하게 합니다.터미널에서 로컬 run 디렉토리 경로를 확인하세요. 이 디렉토리에는 데이터 저장소 역할을 하는 .wandb 파일이 포함되어 있습니다. 이미지 로깅의 경우, W&B는 이미지를 클라우드 스토리지에 업로드하기 전에 media/images 하위 디렉토리에 저장합니다.AWS Batch, ECS 등의 클라우드 인프라와 W&B Sweeps를 함께 사용할 수 있나요?
AWS Batch, ECS 등의 클라우드 인프라와 W&B Sweeps를 함께 사용할 수 있나요?
sweep_id를 게시하려면, 이러한 에이전트들이 sweep_id를 읽고 실행할 수 있는 메소드를 구현하세요.예를 들어, Amazon EC2 인스턴스를 시작하고 거기서 wandb agent를 실행하세요. SQS 큐를 사용하여 여러 EC2 인스턴스에 sweep_id를 브로드캐스트합니다. 그러면 각 인스턴스는 큐에서 sweep_id를 가져와 프로세스를 시작할 수 있습니다.Sweeps와 SageMaker를 함께 사용할 수 있나요?
Sweeps와 SageMaker를 함께 사용할 수 있나요?
requirements.txt 파일을 생성하세요. 인증 및 requirements.txt 파일 설정에 대한 자세한 내용은 SageMaker 인테그레이션 가이드를 참조하세요.SageMaker와 W&B를 사용하여 감성 분석기를 배포하는 방법은 Deploy Sentiment Analyzer Using SageMaker and W&B 튜토리얼을 확인하세요.
동일한 머신에서 계정 간에 어떻게 전환하나요?
동일한 머신에서 계정 간에 어떻게 전환하나요?
시스템 메트릭은 얼마나 자주 수집되나요?
시스템 메트릭은 얼마나 자주 수집되나요?
코드를 테스트할 때 wandb를 끌 수 있나요?
코드를 테스트할 때 wandb를 끌 수 있나요?
wandb.init(mode="disabled")를 사용하거나 WANDB_MODE=disabled를 설정하세요.wandb.init(mode="disabled")를 사용해도 W&B가 WANDB_CACHE_DIR에 Artifacts를 저장하는 것은 방지되지 않습니다.당신의 툴이 트레이닝 데이터를 추적하거나 저장하나요?
당신의 툴이 트레이닝 데이터를 추적하거나 저장하나요?
wandb.Run.config.update(...)에 SHA 또는 고유 식별자를 전달하세요. W&B는 wandb.Run.save()가 로컬 파일 이름과 함께 호출되지 않는 한 데이터를 저장하지 않습니다.결제 수단을 어떻게 업데이트하나요?
결제 수단을 어떻게 업데이트하나요?
- 프로필 페이지로 이동: 먼저 사용자 프로필 페이지로 이동합니다.
- 조직 선택: Account 선택기에서 관련 조직을 선택합니다.
- 결제 설정 접속: Account 아래에서 Billing을 선택합니다.
- 새 결제 수단 추가:
- Add payment method를 클릭합니다.
- 새 카드 세부 정보를 입력하고 이를 기본(primary) 결제 수단으로 만드는 옵션을 선택합니다.
참고: 결제를 관리하려면 조직의 결제 관리자(billing admin)로 지정되어 있어야 합니다.
Report에 CSV 업로드하기
Report에 CSV 업로드하기
wandb.Table 형식을 사용하세요. Python 스크립트에서 CSV를 로드하고 이를 wandb.Table 오브젝트로 로그하세요. 이 작업은 데이터를 Report에서 테이블로 렌더링합니다.Report에 이미지 업로드하기
Report에 이미지 업로드하기
/를 누르고 Image 옵션으로 스크롤한 다음, 이미지를 Report로 드래그 앤 드롭하세요.
W&B 팀 멤버들이 내 데이터를 볼 수 있나요?
W&B 팀 멤버들이 내 데이터를 볼 수 있나요?
W&B 서비스 중단이 발생했나요?
W&B 서비스 중단이 발생했나요?
wandb.init이 내 트레이닝 프로세스에 어떤 영향을 주나요?
wandb.init이 내 트레이닝 프로세스에 어떤 영향을 주나요?
wandb.init()이 실행되면 API 호출이 서버에 run 오브젝트를 생성합니다. 메트릭을 스트리밍하고 수집하기 위해 새로운 프로세스가 시작되어 메인 프로세스가 정상적으로 기능할 수 있게 합니다. 스크립트가 로컬 파일에 기록하는 동안 별도의 프로세스가 시스템 메트릭을 포함한 데이터를 서버로 스트리밍합니다. 스트리밍을 끄려면 트레이닝 디렉토리에서 wandb off를 실행하거나 WANDB_MODE 환경 변수를 offline으로 설정하세요.Sweep이 실행 중인 동안 Python 파일을 수정하면 어떻게 되나요?
Sweep이 실행 중인 동안 Python 파일을 수정하면 어떻게 되나요?
- Sweep이 사용하는
train.py스크립트가 변경되어도, Sweep은 원래의train.py를 계속 사용합니다. train.py스크립트가 참조하는 파일(예:helper.py스크립트의 헬퍼 함수)이 변경되면, Sweep은 업데이트된helper.py를 사용하기 시작합니다.
Artifacts는 어디에 다운로드되며, 이를 어떻게 제어할 수 있나요?
Artifacts는 어디에 다운로드되며, 이를 어떻게 제어할 수 있나요?
artifacts/ 폴더에 다운로드됩니다. 위치를 변경하려면:-
wandb.Artifact().download에 경로를 전달하세요: -
WANDB_ARTIFACT_DIR환경 변수를 설정하세요:
왜 CSV 메트릭 내보내기에서 단계(steps)가 누락되나요?
왜 CSV 메트릭 내보내기에서 단계(steps)가 누락되나요?
run.history API를 통해 제공되지 않을 수 있습니다. 전체 run 이력에 엑세스하려면 Parquet 형식을 사용하여 run history Artifact를 다운로드하세요:이것은 Python에서만 작동하나요?
이것은 Python에서만 작동하나요?